Testing distributed systems at scale is typically a costly yet necessary process. At Alluxio we take testing very seriously as organizations across the world rely on our technology, therefore, a problem we want to solve is how to test at scale without breaking the bank.
In this blog we are going to show how the maintainers of the Alluxio open source project build and test our system at scale cost-effectively using public cloud infrastructure. We test with the most popular frameworks, such as Spark and Hive, and pervasive storage systems, such as HDFS and S3. Using Amazon AWS EC2, we are able to test 1000+ worker clusters, at a cost of about $16 per hour.
Read the full length Technical White Paper if you are interested in the following takeaways as this blog is an abbreviated version:
- Advice for users looking to test their software at massive scale on public-cloud infrastructure
- How the Alluxio maintainers test Alluxio at scale
- Tuning Alluxio to operate at scale
- Challenges that one may face when experimenting with large scale distributed systems along with their resolutions
Test Distributed Systems at Scale
One of the main challenges that faces software engineers is properly testing code before releasing it to users. Those challenges are compounded further when the software is run across hundreds or thousands of machines at the same time, while communicating and coordinating with one another.
Many distributed systems for “big data” are designed to scale horizontally, but until someone really invests the time and resources into testing them in a real environment, it’s difficult to tell up to what number the implementation will actually scale to. This is due to various types bottlenecks which may be tough to uncover during small-scale testing. Many times the users are stressing the systems to their limits well before developers are able to verify how far the systems can be pushed.
So why don’t developers just build large clusters and test their deployments well before the users? It all comes to down to time and money. Provisioning clusters with thousands of nodes is expensive and time consuming. Many companies will hire several full-time engineers in order to maintain a single cluster. Many engineering teams simply don’t have the resources available to them to install, launch, and test their software on thousands of nodes on a regular basis. The maintainers of Alluxio have done our best to mitigate this so that we can test and fully vet all features at scale before release.
Test Alluxio At Scale
What is Alluxio
For the uninitiated, Alluxio is an open-source virtual distributed file system that provides a unified data access layer for big data and machine learning applications in hybrid and multi-cloud deployments. Alluxio enables distributed compute engines like Spark, Presto or Machine Learning frameworks like TensorFlow to transparently access different persistent storage systems (including HDFS, S3, Azure and etc) while actively leveraging in-memory cache to accelerate data access.
Alluxio follows a master-worker architecture. The master is responsible for handling the metadata for the entire cluster while the workers handle data transfer, storage, and retrieval. If you are interested in learning more about the Alluxio architecture we recommend reading our architecture documentation.
How We Test
Most scaling problems that Alluxio users face are typically not related to the size of data stored in Alluxio. Rather, many issues are due to the metadata size (which are proportional to the number of files and directories) and overhead of executing some operations when there is a large number of workers. For the maintainers here, the focus of the scalability test is to verify the correctness of features and measure performance of certain operations after launching lots of Alluxio workers and inserting a lot of files/directories.
To simulate large clusters without the need to launch hundreds or thousands public-cloud instances, we launch multiple docker containers from the alluxio image on a single EC2 instance. This saves cost and time compared to launching a second Alluxio worker on a second instance. Launching multiple workers per cloud instance also allows us to squeeze as many of the resources out of the instances as possible. By carefully selecting the instance types it is possible to fit as many as 100 Alluxio workers on a single instance! Each worker gets access to its own small ramdisk which can be anywhere 64MB-256MB in size.
With this configuration the entire footprint of an Alluxio worker typically stays within ~1.2GB of RAM including the ramdisk. With the help of some automation tools we are able to deploy and tear down 1000-worker clusters in less than 15 minutes.
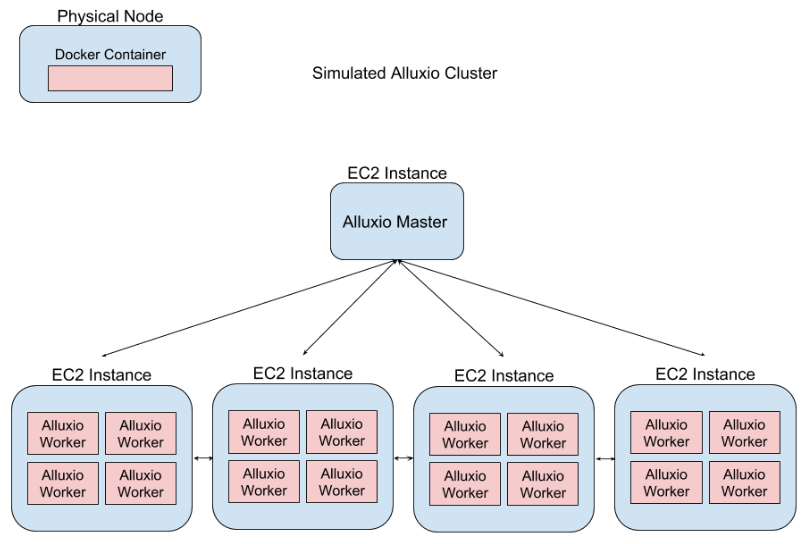
On the other hand, multiple workers running on the same node at a time will be in contention for the same resources in a single system. This creates bottlenecks which one would not normally see. For this reason, these simulated deployments cannot be used to run performance tests and compare results against real clusters. It is, however, still possible to use these clusters for feature verification. It is still possible to test Alluxio for functional correctness; ensuring that new and old features work properly in end-to-end test scenarios where our clusters contain thousands of workers.
We do not, however, containerize the master process. It exists on its own EC2 instance separate from workers similar to a real environment. Even with containerized workers it is still possible to capture information about the performance of the master in this architecture. Mainly, it is still possible record the performance of metadata operations through the master which are critical to the overall performance of Alluxio and its ability to handle thousands of concurrent clients.
It turned out non-trivial to implement such testing infrastructures on public clouds like AWS to support thousand-worker clusters. We faced and addressed quite a few challenges including socket port assignment, DNS configuration, container footprint and memory constraints, configuration tuning for Alluxio service and also the operating systems. The Challenges, Results, and Future Work These are covered in other sections in the full length Technical White Paper. including Challenges, Results, and Future Work.
Hope the approaches described in this paper can help you save some $$, a lot more than the cost of a large pizza!