This post is guest authored from our friends at Tencent: Can He
Download or print the case study here
Tencent is one of the largest technology companies in the world and a leader in multiple sectors such as social networking, gaming, e-commerce, mobile and web portal. Tencent News, one of Tencent’s many offerings, strives to create a rich, timely news application to provide users with an efficient, high-quality reading experience. To provide the best experience to more than 100 million monthly active users of Tencent News, we leverage Alluxio with Apache Spark to create a scalable, robust, and performant architecture.
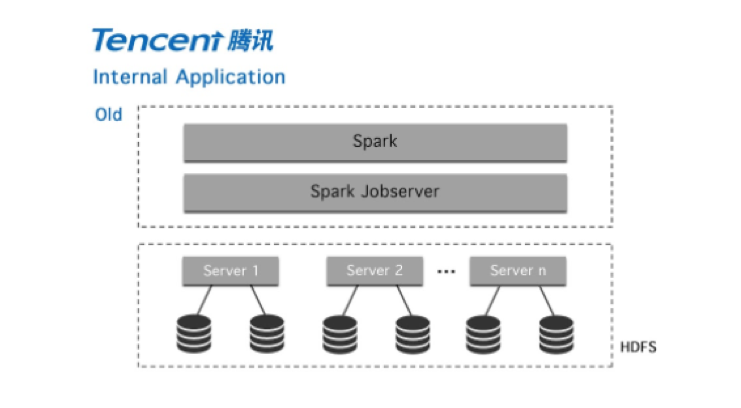
Our goal at Tencent News is to deliver the best experience for every user, and that requires our jobs to complete on the order of seconds. Prior to adopting Alluxio, we ran Spark jobs in a computation cluster of 150 dedicated servers and pulled data from an HDFS cluster served outside this computation cluster in our data center.
This architecture ensures our Spark jobs can exclusively leverage the dedicated computation resource for performance isolation. On the other hand, it also creates data access challenges when the data to pull is large or the machines/network are under high load. During peak times when the data required by a Spark data processing job increases in size, or there is a heavy workload on the cluster, Spark jobs are not able to guarantee the ability to cache the data as RDD in memory and thus read data from disk due to resource contention.
This results in slow job completion, or worse, failures which take a long time to relaunch the job and reload the data, both of which are unacceptable for our business requirements for customer experience.
As a result, we needed a data solution to ensure that Spark jobs can read data with high and stable performance. We surveyed the available technologies, and found Alluxio to be the missing piece of our architecture.
We deploy Alluxio as the in-memory data layer for Spark jobs, on each machine of the computation cluster running Spark jobs, and change Spark jobs to read from or write to Alluxio instead of caching data inside Spark processes. The benefit is two-fold:
- By decoupling storage from computation, it enabled Alluxio to store the data pulled from HDFS when the data is accessed for the first time, then serve the data locally on the nodes where Spark compute was running. As a result performance is much higher than previously while also providing SLA guarantee that meets our stringent requirements on job completion time.
- Alluxio deployment can be scaled up or down dynamically according to the available memory resource. Changing this layer between compute and storage is transparent to application and independent from the size of the data Spark needed to compute.
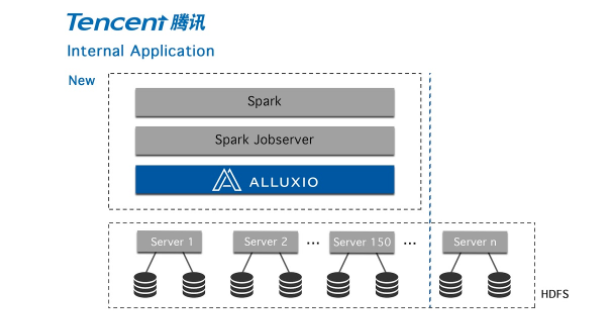
With this new architecture, we now have a highly scalable, predictable, and performant platform for serving the critical missions of Tencent News to our user base. We have been running Alluxio on over 600 nodes and we plan to expand the footprint further.