Author: Shuang Li (Shuang is a big data engineer at Netease Games, developing and maintaining OLAP related solutions in the data warehouse. He works closely on Apache Kylin and Presto as well as HBase. Shuang graduated from South China University of Technology.)
Background
As one of the world’s leading online game company, Netease Games is the operator for many popular online games in China like “World of Warcraft” and “Hearthstone”. Netease Games also has developed quite a few popular games on its own such as “Fantasy Westward Journey 2”, “Westward Journey 2”, “World 3”, “League of Immortals”.
The strong growth of the business drives the demand to build and maintain a data platform handling a massive amount of data and delivering insights promptly from the data. Specifically, everyday there is about 30TB of raw data collected in our data warehouse; the raw data is further processed to intermediate data in the operational data store (ODS) tables by ETL jobs and becomes several times larger. Given our data scale, it is very challenging to support high-performance ad-hoc queries to the data with results generated in a timely manner.
To achieve this goal, a common approach is to build “SQL on Hadoop” including Hive on MapReduce, Hive on Tez or SparkSQL. Actually Netease Games have already built many internal services using these approaches. However, we observed a few limitations to meet our demanding performance requirements when running ad-hoc queries which requires to respond in 2-15 seconds on average:
Limitations of the existing stack
- Hive on MapReduce works well for batch processing jobs less sensitive to response time such as ETL jobs. Depending on the complexity of individual queries, these jobs typically complete in a few minutes and sometimes hours, not in seconds.
- Hive on Tez optimizes the engine and makes the execution plan of tasks in a Directed Acyclic Graph (DAG). Its performance in general is better compared to the Hive on MapReduce. But based on our tests, the response time is still 30 seconds or more and thus insufficient.
- SparkSQL also leverages DAG and leverages in-memory computation. We observed improved performance based on SparkSQL with the response time in 10 to 30 seconds. However, this approach still has a few limitations in our environment.
- Every SparkSQL job needs to apply for resources from YARN. When the YARN cluster is busy, the time for applying resources is can be the order of minutes, which will greatly slow down the query.
- SparkSQL jobs often trigger a lot of HDFS IOs because our data source is HDFS. In addition, by its default shuffle process, intermediate data that exceeds the size of the Executor memory will be written to HDFS too. However, in our production environment, the latency and throughput of HDFS data nodes are very unstable especially at the peak of offline operations, adding a large variance of the query response time.
A New Approach
In August of 2017, Netease Games decided to build a real-time query platform that can analyze the logs of individual game players to provide insights to business analytics. The previous solution was built on top of HBase and co-processor, which required full table scans in HBase due to multiple slow (e.g., a few minutes) queries for maintenance, and also required slow, expensive and complex steps to export and transform tables from Hive into HBase. As a result, building a new ad-hoc query platform became our high priority. After multiple iterations with the potential users of this platform, we concluded the following requirements for the new solutions:
- Good and stable query performance: The query performance should be significantly better than the previous solution. On average the expected time of the business query must be within 10 seconds with small variance.
- No data ETL: the platform can query Hive tables directly, without transferring data between different storage systems.
- Better user experience: the users strongly request a web UI to show the progress of adhoc queries. in case the query takes a long time to complete, user can at least check the progress.
Based on the above requirements, we decided to build the new platform based on a stack of open source software including Presto and Alluxio:
- Presto is an open source, distributed SQL query engine based on the MPP architecture that provides interactive speed of data analysis at large-scale in production data warehouses.
- Alluxio is a memory-speed storage solution that plays a key role in performance acceleration especially in the architectures where compute and storage is separated. It accelerates the reading performance by caching data close to compute in a storage medium such as MEM, SSD, HDD and managed the data transparently.
Benefits of the Presto + Alluxio stack
Our architecture based on Presto and Alluxio provides the following benefits:
- Presto based on its MPP architecture provides the excellent performance of ad-hoc queries.
- After the initial reads from HDFS, subsequent data request will be served from in-memory storage of Alluxio. We even preload frequently used data from HDFS to Alluxio to make the entire data processing in-memory to reduce performance variance.
- Presto can directly query the data in Hive without additional data ETL.
- Presto also checks the progress percentage of the process, which is convenient to be integrated into the business frontend.
- By using Alluxio to manage storage and interfacing with HDFS to serve Presto in a separate compute cluster, the resource-isolated satellite cluster is simple and easy to maintain without the need for additional ETL steps.
Architecture
The following figure described our architecture:
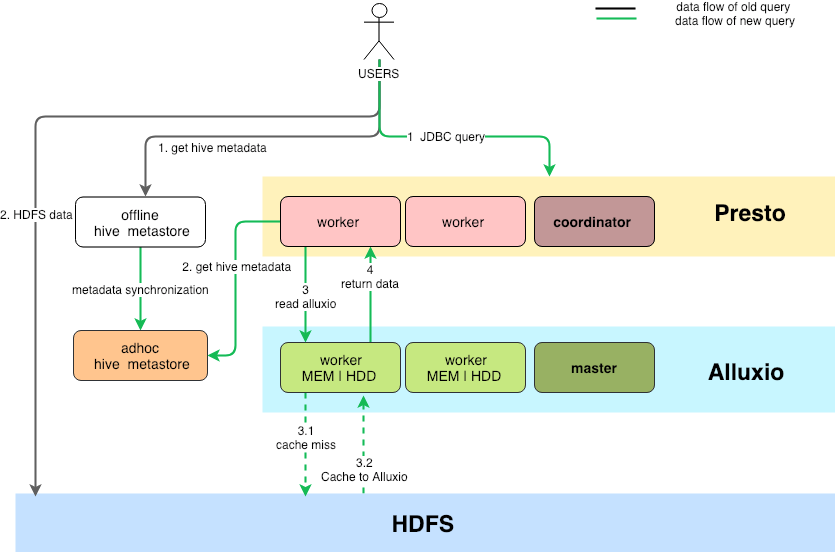
Configuration & deployment details
- To ensure efficient and stable query performance, the service of Presto and service of Alluxio are both deployed on the same satellite cluster, separate from the HDFS datanode cluster that stores and serves the entire set of data. This architecturally guarantees that the query framework has exclusive isolation of computing and memory resources. In this satellite cluster, Presto and Alluxio are colocated: the Presto coordinator and the Alluxio master are deployed on the same node. Similarly, the Presto and Alluxio workers are deployed on the same node. Currently the largest cluster has 100 nodes.
- Due to the cost of memory resources, Alluxio’s storage does not use memory as a full storage, but sets up tiered storage with two layers: the memory layer (MEM) and hard disk layer (HDD). We configured 10GB of memory and 800G of HDD storage for each Alluxio worker, and Alluxio manages the resource through the built-in cache eviction strategy.
- We setup an isolated Hive metastore instance dedicated for Presto. This is because our common Hive metastore has unstable performance during peak hours of batch processing jobs. In our environment, the 99-percentile latency of the
get_tableapi can be 10x worse during peak times. - Since the entire data is stored in HDFS which is the source of the truth, the data cached in Alluxio needs to synchronize with the data in HDFS. Here is the sync logic for us:
- Data sync: currently we do not write data back to HDFS from Alluxio for adhoc queries, so the path of data sync is only from HDFS to Alluxio;
- Metadata sync: before our solution, the locations of Hive tables were all in HDFS. After adding Alluxio as one more option without affecting the current offline jobs, we developed a metadata synchronization tool to help users automatically synchronize updated tables to the Hive, by specifying a whitelist of tables.
- Other recommendations on configurations and performance:
- Presto and Alluxio’s integration configuration can be found in Documentation.
- The adhoc query has stronger requirements for network throughput. It is recommended that dual-gigabit bonding ethernet on the machines where Presto+Alluxio are deployed.
- We recommended that the Hive table in the adhoc scene adopts the format of ORC and Snappy. By using the ORC column storage and the high compression ratio of Snappy, the amount of data input to the Presto source stage and the storage resources of Alluxio can be greatly reduced.
Performance Evaluation
Performance comparison of SQL on Hadoop without Alluxio
- The size of the data: 150 million rows, 50 fields, 46 GB
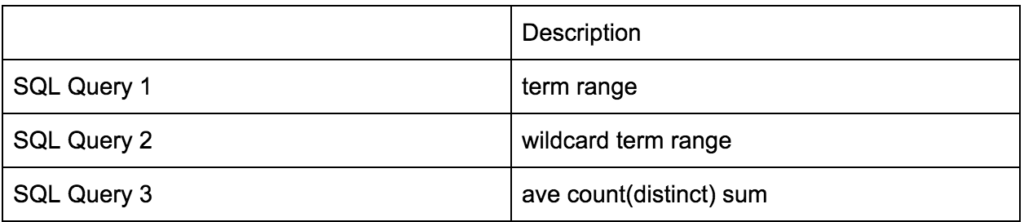
- Description of our test SQL queries:
The test results are:
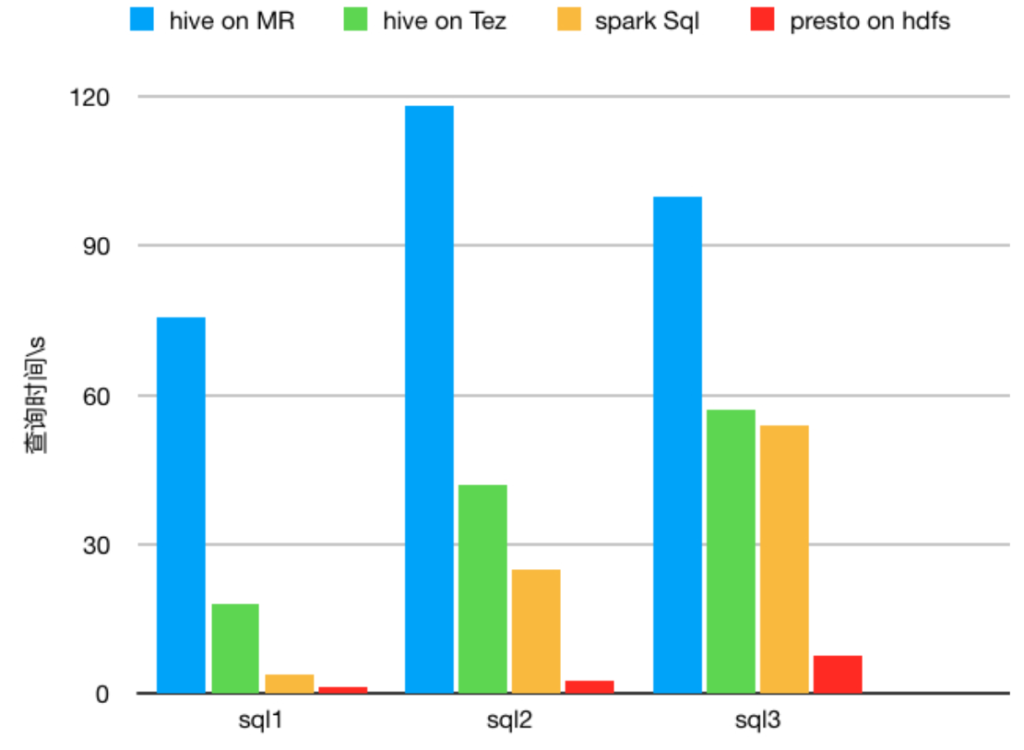
Presto Performance comparison of single concurrent queries with or without Alluxio cache

The x-axis is the query time, and the query is performed every 1 minute; the ordinate is the time of the query, the unit is ms. In the above figure, the green line is the query performance curve of Presto+Alluxio; the red line is the query performance curve of Presto + non-Alluxio. From the results, the query delay of Alluxio Cache has obvious optimization, and the query time is very stable.
Issues Addressed
During our deployment, some problems were also identified:
- Alluxio do not support to measure and report some performance related metrics that we are interested in. In our current deployed version v1.7.1, the current metrics are more related to RPC Ops, there are very few performance metrics, such as RPC delay of worker thrift server, thread pool usage of thrift server, GC status, etc.
- There is still room for Alluxio to optimize its RPC performance. Our performance tests with high concurrency show occasionally worker timeout occurs, and we suspect it is related to a suboptimal thread pool configuration. The community is planning a major upgrade in its RPC framework in Alluxio 2.0.
- Performance issues of Alluxio master metadata: Users familiar with namenode may know that, if the number of blocks and files of a single namenode exceeds a certain threshold, system performance will be degraded, and this single point of failure will risk the entire service. For us, the size of the metadata loaded into Alluxio is currently limited using whitelisting. A good news is that the community has a plan to support at least 1 billion files in Alluxio 2.0.
Future Plan
Currently, with the help of this platform, there are already a lot of interactive query services running using Presto+Alluxio, which greatly expands the requirements of interactive query business scenarios other than real-time computing and offline computing. In most of the cases, Alluxio can improve the response time of queries, so for next steps we will consider deploying services on a larger scale widely and available to more business applications. At the same time, we will be more active in community activities, focusing on Alluxio performance, stability and exploring more business applications. Specifically:
- Test Presto+Alluxio on YARN framework: The current framework is a cluster independent of YARN. Due to the particularity of ad-hoc business, its concurrency is not particularly high, so it will cause a certain amount of waste of resources. Yarn-based Presto+Alluxio can solve this problem well, and it also offers a lot of more opportunities. In fact, there is already a yarn-based Presto+Alluxio test environment, which is undergoing functional and performance testing.
- Interfacing Alluxio with more data warehousing services on the Alluxio unified namespace.
- Discover more applications for Alluxio reading and writing with more production teams.
In the end, I especially acknowledge the help from the Alluxio maintainer Bin Fan and the open source community for their support during our exploration!