Highlights:
- Improved customer responsiveness and increased revenue
- Interactive analytics/reporting and faster time to insight
Download or print the case study here.
Myntra, a division of Flipkart, is a leading Indian e-commerce fashion retailer offering customers a wide range of clothing and other merchandise through a mobile application. Mobile devices drive 95 percent of the traffic to Myntra and smartphones generate 75 percent of sales. Myntra is at the forefront of several important trends in the Indian retail market. Key drivers are the growing penetration of smartphones, the growth of income and purchasing power of consumers under 30 years old, and the increasing desire of Indian consumers to spend on fashion and luxury products.
Providing a tailored experience is the key to customer satisfaction and revenue growth. We achieve this by analyzing the data on how customers interact with the application. Understanding shopping patterns, ad responses, and reporting on clicks provides the insight required to provide customers relevant information, recommendations, and products. To achieve this we built a new big data pipeline running in the Microsoft Azure cloud.
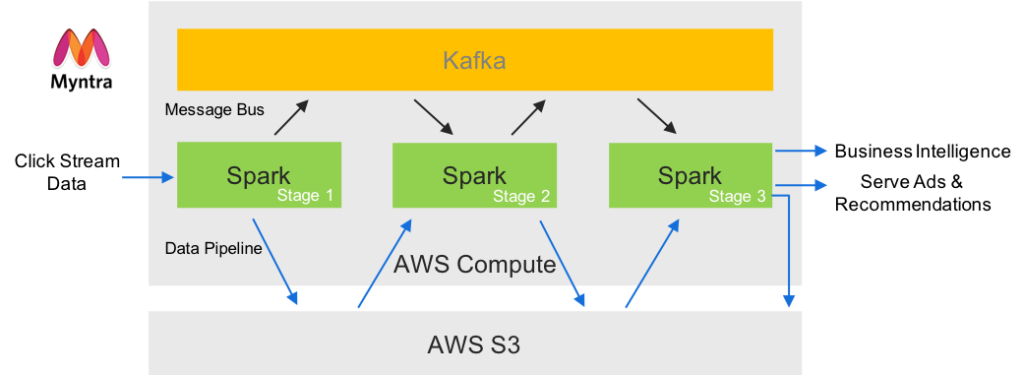
Initially, clickstream data was processed in a pipeline using Spark as the compute engine, Kafka as the messaging bus, and Presto for internal reporting and metrics data. Spark reads data from Azure Blob storage (which is object storage) and then after processing Spark writes data back into Azure Blob storage.
This process was time-consuming and inefficient for two primary reasons. First, because Azure Blob is an object storage rather than a file system the process of pulling files by Spark is inefficient. Second, Spark often has to read the same file multiple times when running aggregations, compounding the first problem. This prevented us from providing interactive responses to our customers as well as generally increased the amount of time to get business insights. As a result, we investigated technologies and methods to help streamline the data pipeline.
While looking for ways to streamline our data pipeline, we learned about Alluxio, an open source, memory speed, virtual distributed file system. We deployed Alluxio as the shared data layer for all of the intermediate stages in the data pipeline. By reading and writing data in Alluxio, the data can be read concurrently and stay in memory for the next stage of the pipeline. This increased the performance by speeding up the entire pipeline, and increased overall throughput of the pipeline allowing us to provide interactive response to our app users.
With this, we are able to see our customers spend more time on the application, a primary measure of customer success.
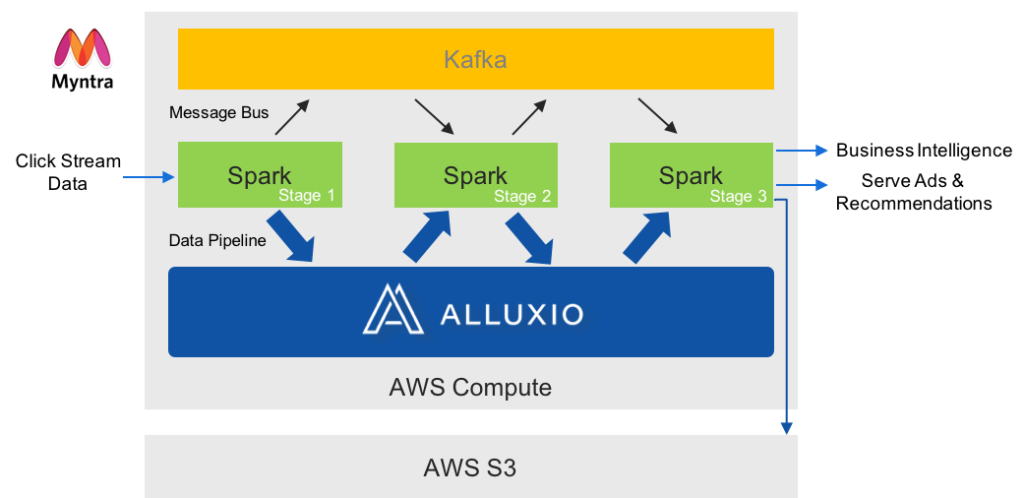
enabled interactive response to application users.
Additionally, we found that most reports were generated using the same data set. In order to speed this up, we decided to store the data in Alluxio and Azure blob store, with the reports being generated against the data in Alluxio. This greatly reduced the time required to generate reports and provide valuable insights into our business.
Results Summary:
With Alluxio, Myntra is now able to:
- Provide interactive response and improved customer experience to our users which in turn leads to increased revenue.
- Provide interactive reporting for our analysts, enabling faster and higher quality insights into our business and lower operational costs.
Alluxio is a critical component of our data processing pipeline architecture, significantly improving customer satisfaction, increasing revenue, and accelerating our ability to generate actionable business intelligence from our data. We hope others in the Alluxio community can benefit from our experience and are happy to have contributed the documentation for deploying Alluxio with Azure Blob Store to the open source community at Alluxio.org