Introduction
In the age of growing datasets and increased computing power, deep learning has become a popular technique for AI. Deep learning models continue to improve their performance across a variety of domains, with access to more and more data, and the processing power to train larger neural networks. This rise of deep learning advances the state-of-the-art for AI, but also exposes some challenges for the access to data and storage systems. In this article, we further describe the storage challenges for deep learning workloads and how Alluxio can help to solve them.
Data Challenges of Deep Learning
Deep learning has become popular for machine learning because of the availability of large amounts of data, and typically more data leads to better performance. However, there is no guarantee that all the training data are available to deep learning frameworks (Tensorflow, Caffe, torch). For example, deep learning frameworks have integrations with some existing storage systems, but not all storage integrations are available. Therefore, a subset of the data may be inaccessible for training, resulting in lower performance and effectiveness.
Also, there is a variety of storage options for users, with distributed storage systems (HDFS, ceph) and cloud storage (AWS S3, Azure Blob Store, Google Cloud Storage) becoming popular. However, practitioners interact with these distributed and remote storage systems in an unfamiliar way from simply using the local file system on the local machine. It can be difficult to properly configure and use new and different tools for each storage system. This makes accessing data from diverse systems difficult for deep learning.
Lastly, the growing trend of separating compute resources from storage resources necessitates using remote storage systems. This is common for cloud computing and enables on-demand resource allocation, which can lead to higher utilization, flexible elasticity, and lower costs. However, when remote storage systems are used for deep learning training data, that means data must be fetched over the network, which can increase the training time for deep learning. The extra network IO will increase costs and increase the time to process the data.
How Alluxio Helps Deep Learning Storage Challenges
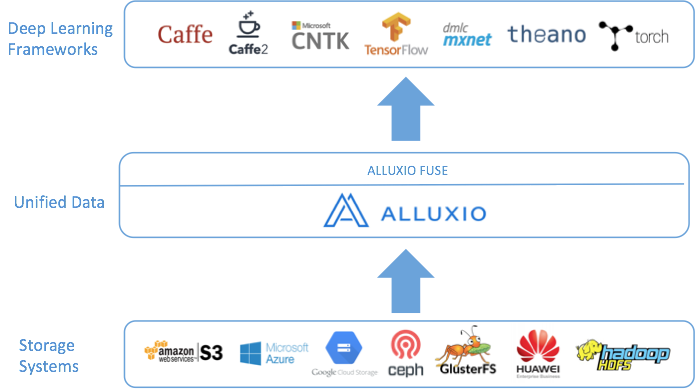
While there are several data management related issues with deep learning, Alluxio can help with the data access challenges. Alluxio in its simplest form is a virtual file system which transparently connects to existing storage systems and presents them as a single system to users.
Using the Alluxio unified namespace, many storage technologies can be mounted into Alluxio, including cloud storage like S3, Azure, and GCS. Because Alluxio can already integrate with storage systems, deep learning frameworks only need to interact with Alluxio, to be able to access all the data from all storage. This opens the door for training to be performed on all data from any data source, which can lead to better model performance.
Alluxio also includes a FUSE interface for a convenient and familiar use experience. With Alluxio FUSE, an Alluxio instance can be mounted to the local file system, so interacting with Alluxio is as simple as interacting with local files and directories. This enables users to continue to use familiar tools and paradigms to interact with their data. Since Alluxio can connect to multiple disparate storage, this means any data from any storage can look like a local file or directory.
Finally, Alluxio also provides local caching of frequently used data. This is particularly useful when the data is remote from the computation, such as the disaggregate compute from storage environment. Since Alluxio can cache the data locally, network IO is not incurred for accessing the data, so deep learning training can be more cost effective, and take less time.
Setting up Alluxio FUSE
This section describes how to set up Alluxio to access training data of ImageNet in S3, and allow deep learning frameworks to access the data through FUSE.
To install Alluxio, download the latest tarball with the bundled FUSE connector from the Alluxio website. Note that the distributions before Alluxio 1.7 are not compiled with Java 8 so it does not have FUSE connector built-in which requires Java 8+. If you want to use Alluxio 1.6 or before with FUSE, please follow the instructions at this documentation to manually build the distribution.
Next, extract the tarball and go into the directory:
$ tar -xvf alluxio-1.7.0-hadoop-2.8-bin.tar.gz
$ cd alluxio-1.7.0-hadoop-2.8
Configure Alluxio to use the default settings. First, create the conf/alluxio-site.properties file from the template.
$ cp conf/alluxio-site.properties.template conf/alluxio-site.properties
Afterwards, open the file (conf/alluxio-site.properties) and uncomment these properties.
alluxio.master.hostname=localhost
alluxio.underfs.address=${alluxio.work.dir}/underFSStorage
Then, specify the worker memory size in Worker properties
alluxio.worker.memory.size=20GB
We used 20GB which is large enough to hold the subset of imagenet for benchmarking.
Next, we will format Alluxio in preparation for starting Alluxio. Run the following command. This command will format the Alluxio journal so the master can start correctly.
$ ./bin/alluxio format
Afterward you can see the journals are created at the working directory ./journal
You can now start Alluxio. By default, Alluxio is configured to start a master and worker on the localhost. We can start Alluxio on localhost with the following command:
$ ./bin/alluxio-start.sh local SudoMount
You can check that Alluxio has started by visiting http://localhost:19999 to see the status of the Alluxio master.
Next, we’ll mount the training data that is stored in the cloud into a folder in Alluxio. First, we’ll create a folder at the root in Alluxio
$ ./bin/alluxio fs mkdir /training-data
Then, we can mount the ImageNet data stored in an S3 bucket into path /training-data/imagenet
$ ./bin/alluxio fs mount /training-data/imagenet/ s3a://alluxio-tensorflow-imagenet/ --option aws.accessKeyID=<ACCESS_KEY_ID> --option aws.secretKey=<SECRET_KEY>
Note this command takes options to pass the S3 credentials of the bucket. And these credentials are associated with the mounting point, so that the future accesses won’t need the credentials.
Next, we’ll start the Alluxio-FUSE process. This requires libfuse for Linux or osxfuse for macOS. For more usage and limitation about FUSE, you can check out the documentation here.
First, we’ll create a folder /mnt/fuse, change its owner to the current user (ec2-user in this tutorial), and make it read-write.
$ sudo mkdir -p /mnt/fuse
$ sudo chown ec2-user:ec2-user /mnt/fuse
$ chmod 664 /mnt/fuse
Next, we’ll run the Alluxio-FUSE shell to mount Alluxio folder training-data to the local folder /mnt/fuse.
$ ./integration/fuse/bin/alluxio-fuse mount /mnt/fuse /training-data
Now the FUSE process should have started, and you can check its status with:
$ ./integration/fuse/bin/alluxio-fuse stat
Now you can go the mounted folder and browse the data, it should display the training data stored in the cloud.
$ cd /mnt/fuse
$ ll
This folder is ready for the deep learning frameworks to use, which would treat the Alluxio storage as if it’s a local folder. We’ll use this folder for the Tensorflow training in the next section
Using Tensorflow on Alluxio FUSE
We use Tensorflow as an example deep learning framework in this tutorial to show how Alluxio can help data access and management.
We run this tutorial on an EC2 p2.8xlarge machine which has 8 GPUs (NVIDIA Tesla K80) and 32 vCPUs, and installed Tensorflow 1.3.0. We also used the CNN benchmarks created by the Tensorflow organization as an example of deep learning workloads.
According to its own homepage, it contains implementations of several popular convolutional models such as AlexNet and GoogleNet for image classification. And it is designed and implemented to be as fast as possible, incorporating several techniques (e.g. input pipeline, parallelized IO reads, training data preprocessing) for building high-performance models.
To access the training data in S3 via Alluxio, with the Alluxio FUSE, we can simply pass the path /mnt/fuse/imagenet to the parameter data_dir of the benchmark script tf_cnn_benchmkars.py.
After mounting the under storage once, data in various under storages becomes immediately available through Alluxio and can be transparently accessed to the benchmark without any modification to either Tensorflow or the benchmark scripts. This greatly simplifies the application development, which otherwise would need the integration of each particular storage system as well as the configurations of the credentials.
On top of the unification benefit, Alluxio can also bring performance benefits. The benchmark evaluates the throughput of the training model from the input training images in the unit of images/sec. The training in fact involves three stages of utilizing different resources:
- Data reads (I/O): choose and read image files from source.
- Image Processing (CPU): Decode image records into images, preprocess, and organize into mini-batches.
- Modeling training (GPU): Calculate and update the parameters in the multiple convolutional layers
By collocating Alluxio worker with the deep learning frameworks, Alluxio caches the remote data locally for the future access and therefore provides data locality. Without Alluxio, slow remote storage may result in bottleneck on I/O and leave the precious GPU resource under utilized. For example, among the benchmark models, we found AlexNet has relatively simpler architecture and therefore it’s more likely to result in an I/O bottleneck when storage becomes slower.
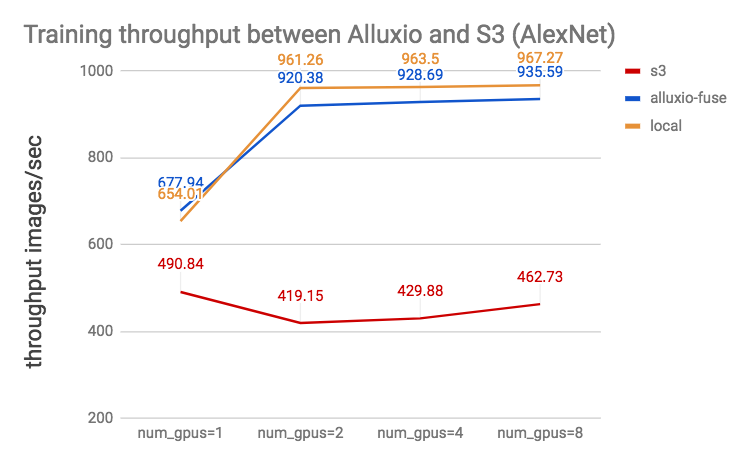
Our benchmark results show that AlexNet bottlenecks on I/O when it reads the training data from S3. Alluxio overcomes this bottleneck and brings nearly 2X performance improvement which is almost the same as reading from a local replicate.
Summary
Alluxio unifies disparate storage systems and provides data access as a local folder to the deep learning frameworks via Alluxio FUSE. With Alluxio, data scientists can gain easy access to a variety of storage systems and flexibility without the compromise on performance.