Introduction
As the amount of data being collected and analyzed by Enterprises continues to grow unabated, more attention is being placed on managing the cost of storing the data relative to performance. Hadoop provides a scalable and fast way of storing and analyzing data, however, the cost of storing data in Hadoop is typically higher compared to alternative technologies like Object Stores.
Object Storage solutions are popular for both on-premise and cloud deployments (e.g. AWS S3) for enterprises looking for scalable, cost effective storage. Unfortunately Object Stores typically provide lower performance compared to Hadoop and developers might be unwilling to make this tradeoff. Vendors often note the cost advantage, and cloud providers are quite transparent about pricing, but the performance tradeoff isn’t always addressed.
Alluxio, a virtual distributed file system, creates a data layer that unifies independent storage systems at memory speed. Data stored in both Hadoop HDFS and Object Stores can be accessed as a single source in a global namespace, allowing enterprises to design a storage solution that takes advantage of lower cost storage without the performance penalty, bringing the best of both worlds.
Alluxio Overview
Alluxio is the world’s first memory-speed virtual distributed file system. It unifies data access and bridges compute frameworks and storage. Applications only need to connect with Alluxio to access object or file data stored in any underlying persistent storage systems. Additionally, the Alluxio architecture enables data access at memory speed, providing the fastest I/O available.
In the big data ecosystem, Alluxio is a data layer between compute and storage. It can bring significant performance improvements, especially spanning data centers and cloud availability zones. Alluxio abstracts objects or files in underlying persistent storage systems and provides shared data access for applications. Alluxio is Hadoop and object store compatible and supports both reading and writing to persistent storage. Existing data analytics applications, such as Hive, HBASE, and Spark SQL, can run on Alluxio without any code changes.
Current Big Data Storage Architecture
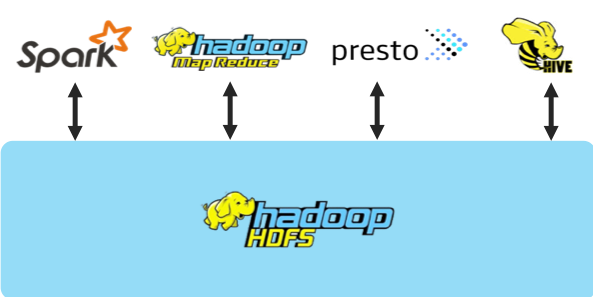
The most common Big Data storage architecture consists of co-located compute and storage, using HDFS as the storage for compute frameworks like MapReduce, Spark, Hive, Presto, etc. as shown in figure 1. Data and compute are located on the same node, providing high performance but creating scalability and cost challenges as compute and storage are tightly coupled. Scaling of storage requires scaling of compute (and vice versa) even when it is not needed. Over time Hadoop clusters can grow very large and accumulate a significant amount of older, less active cold data.
New Big Data Storage Architecture
Deploying Alluxio creates an architecture with a virtual data layer, unifying data stored in both HDFS and Object Stores as shown in figure 2. Performance in the cluster is comparable to an HDFS only configuration since Alluxio caches the data from the Object Store. At the same time, less frequently used data can be moved to the most cost-effective Object Store, and storage and compute can be scaled independently.
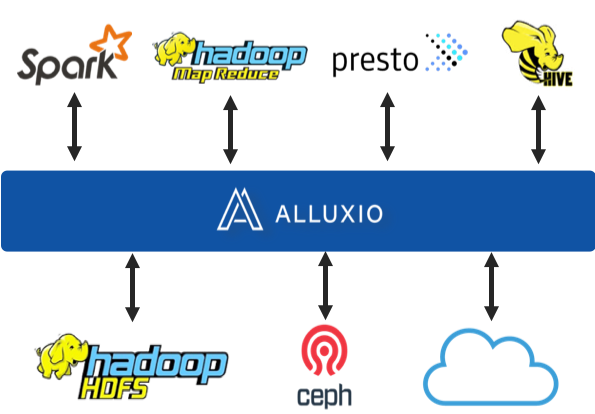
In this storage architecture, Alluxio provides the following capabilities:
- A modern flexible architecture with compute and storage separated. Resources can be scaled and managed independently. Standard APIs and plug-in architecture supports future technologies.
- The unified data layer creates a “virtual data lake.” Objects and files are accessed in the Alluxio global namespace as if they resided in a single system.
- Fast local access to important and frequently used data, without maintaining a permanent copy. Alluxio intelligently caches only required blocks of data, not the entire file.
- Storage costs are optimized by migration of data to lower cost commodity storage without a performance penalty
- Flexibility: Data in Alluxio can be shared across different workloads and compute frameworks such as querying, batch analytics, and machine learning. Support is provided for industry standard interfaces, including HDFS and S3A.
How to deploy and share HDFS and Object storage with Alluxio
To demonstrate the performance impact, we ran a simple test that you can easily replicate in your own environment. For the experiment we created an example configuration using MapReduce, HDFS, Alluxio, and an AWS S3 bucket. The experiment shows an Object Store in the cloud yields similar performance characteristics to on-premise HDFS deployments
The cluster contains six Amazon EC2 instances (of type M4.4XL). The cluster is configured with five Alluxio workers colocated with HDFS DataNodes; each worker had 30GB of memory reserved. NameNode and the Alluxio master reside on the same host and Alluxio is configured with this HDFS deployment as its root file system.
The experiment is run as follows: Teragen is used to generate the data (100GB) which is stored in HDFS Terasort is run against the data via MapReduce Then HDFS and the S3 bucket are mounted to the Alluxio namespace and the existing data is migrated from HDFS to S3 via the Alluxio Unified File System feature Lastly, Terasort is run against the data in S3 via MapReduce
Generate dataset
To feed terasort, generate a 100GB dataset on on-prem HDFS using teragen:
$ hadoop jar /usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar teragen 1000000000 /teraInput
Run Terasort (HDFS)
For baseline performance, run terasort against on-prem HDFS.
$ hadoop jar /usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar terasort /teraInput /teraOutput
Migrate data to S3
The Alluxio unified file system feature provides a simple way to migrate data between supported file systems. Migrating data from on-prem HDFS to S3 will be done using Alluxio shell commands. Mount S3 bucket to Alluxio namespace
$ bin/alluxio fs mount --option aws.accessKeyId=<S3_KEY_ID> --option aws.secretKey=<S3_KEY> /s3-mount s3a://alluxio-terasort/input
Copy dataset to S3 via Alluxio
$ bin/alluxio fs cp -R /teraInput /s3-mount
Depending on your configured write type for Alluxio, you may need to load the data manually into Alluxio space.
$ bin/alluxio fs load /s3-mount
Run Terasort (S3 through Alluxio)
Generate terasort output to on-prem HDFS for getting a reliable performance reading for data read path.
$ hadoop jar /usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar terasort alluxio://<MasterHost:Port>/s3-mount/teraInput /teraOutput
Results
Total duration for the on premise HDFS configuration was 39min, 13sec. Accessing the data from S3 through Alluxio resulted in a total duration of 37min, 17sec, actually almost 5% faster.
Alluxio supports any commercial Object Storage platform supporting standard interfaces, including on-premise and solutions offered by major cloud providers. To try Alluxio for yourself you can download and get started in minutes by accelerating a sample data set in AWS or running the above experiment.