Faster On-Demand Clusters
This is an excerpt from the Accelerating On-Demand Data Analytics with Alluxio whitepaper, which includes a detailed implementation guide in addition to this high level overview.
In the Big Data world, it is often the case that only a subset of the total data is relevant for answering the question at hand. As a result, the total cost of ownership for long running clusters for analytics is high while utilization is low, especially when adopting an architecture of co-locating compute and storage.
The full compute power of the clusters is often unused, since data insights are driven by humans who query on an ad-hoc basis, unlike a data pipeline which continuously runs. The storage capacity of the cluster must also accommodate any data which may be queried against, when in reality the working set is only a small fraction of the total data. Finally, the cluster itself requires significant maintenance and management to ensure performance and isolation between groups using the cluster.
A simple and elegant solution to this problem is the concept of on-demand compute clusters paired with object storage. The proposed architecture addresses the root of the problem by decoupling persistent, long running storage and ephemeral computation. This architecture provides several benefits over the previous continuously running analytics cluster:
- Higher storage cost-effectiveness and scalability – Object storage is cost effective and most providers can scale to arbitrary amounts of data seamlessly
- Higher compute cost-effectiveness and elasticity – Only provision compute resources when necessary and scale the cluster size to fit the task
- Lower cost of maintenance – Clusters are expendable and do not need to be maintained over long periods of time. Users also do not need to worry about interfering with the data as they are only reading a copy.
However, there is also a critical downside to this architecture – lower performance. Object storages are not designed for high I/O throughput, and the speed of the jobs can be unacceptably slow
This is addressed by deploying Alluxio on compute nodes, bringing performance up to memory speeds without requiring a long running cluster or expensive up front costs.
Example Architecture
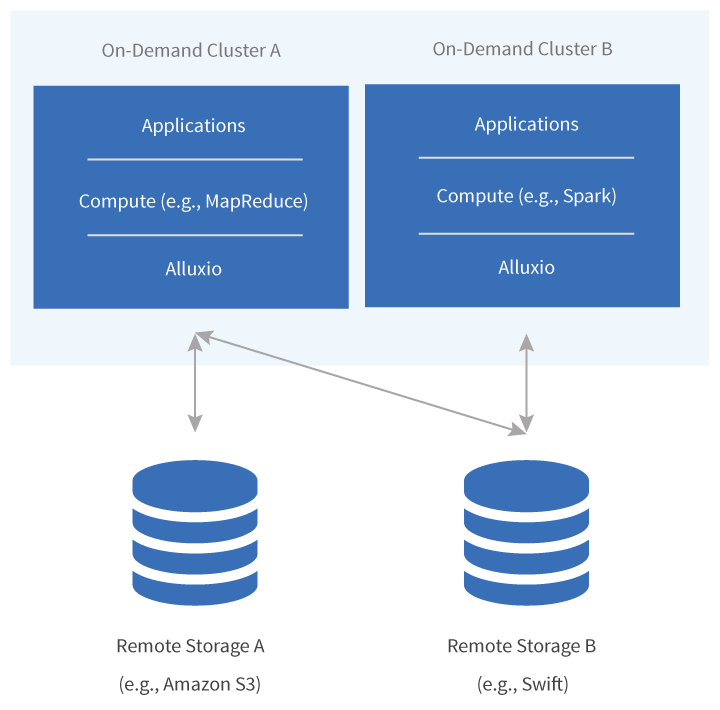
Why Alluxio
Alluxio is a memory-speed virtual distributed storage system deployed in compute clusters. Alluxio virtualizes the underlying storage systems, making any compute written with Alluxio in mind automatically work with any or multiple under storage systems without any code modifications. In addition, Alluxio is designed to be a scale-out distributed system, meaning adding more machines will gracefully accommodate larger datasets and improve performance.
Deploying and leveraging Alluxio is simple and transparent to applications. Applications continue to access the data as if they were running the job against the remote storage, and Alluxio will intelligently keep hot data in memory for subsequent reads. The entire process is transparent to the application and there is no manual ETL required. Once the data is brought into Alluxio, it will be available for all applications of the cluster, drastically improving performance when the same data set is being used multiple times.
Alluxio provides flexibility and efficiency to its users. Any results or transformations which need to be persisted can be done directly through Alluxio which can synchronously propagate the data to an under storage system, ensuring no data is lost. In addition, users have the option of storing temporary or intermediate data in Alluxio memory only, allowing for memory-speed reads and writes.
Conclusion
The high costs and maintenance requirements of long running analytics clusters makes the model of on-demand compute clusters paired with object storage a simpler and more cost-effective solution. By deploying Alluxio alongside the computation frameworks in the compute cluster, we overcome the critical performance shortcoming of the on-demand cluster model. The design of the Alluxio system makes it a perfect choice to provide this core functionality in the stack.
If you are interested in learning more about using Alluxio in an on-demand cluster, download our whitepaper which explains how to setup, deploy, and run jobs on an industry-like on-demand cluster with Alluxio, object storages like S3, and computation frameworks such as Spark.