This is an excerpt from the Accelerating Data Analytics on Ceph Object Storage with Alluxio whitepaper. In addition to the reference architecture in this blog, the whitepaper provides a detailed implementation guide to reproduce the environment.
As the volume of data collected by enterprises has grown, there is a continual need to find efficient storage solutions. Owing to its simplicity, scalability and cost-efficiency object storage, including Ceph, has increasingly become a popular alternative to traditional file systems. In most cases the object storage system, on-premise or in the cloud, is decoupled from compute nodes where analytics is run. There are several benefits of this separation.
- Improved cost efficiency – Storage capacity and compute power can be provisioned independently. This simplifies capacity planning and ensures better resource utilization.
- Ease of manageability – A separation of data from compute means that a single storage platform can be shared by different compute clusters. For example, a cluster hosting long-running services emitting data into object storage may run in conjunction with a data processing cluster to derive insights.
However, a consequence of this architecture is that data is remote to the compute nodes. When running analytics directly on the object store, data is repeatedly fetched from the storage nodes leading to reduced performance. This delay may prevent critical insights from being extracted in a timely manner.
This is addressed by deploying Alluxio on compute nodes, allowing fast ad-hoc analysis of data by bringing performance up to memory speeds with intelligent storage of active archive data close to computation.
Example Architecture
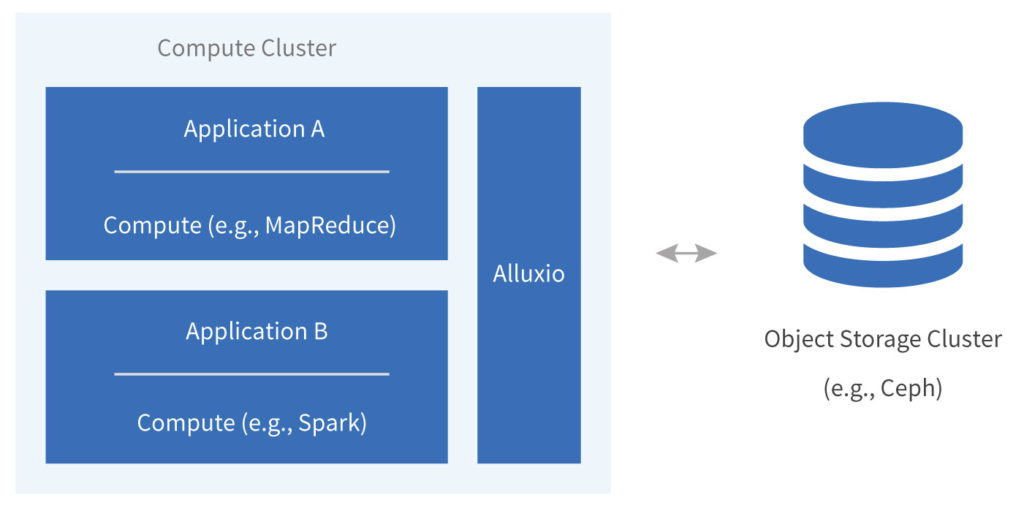
Why Alluxio
Alluxio is a memory-speed virtual distributed storage system. It resides on the compute nodes and scales out with the size of the cluster. Alluxio manages data in-memory and optionally on secondary storage tiers, such as cheaper SSDs and HDDs, for additional capacity. By keeping hot data in-memory on the compute nodes and seamlessly migrating data across any secondary tiers, Alluxio manages to achieve memory-speed access to remote data in most cases. This acceleration is a key enabler of ad-hoc data analysis.
Alluxio also enables sharing data across different compute frameworks and amongst different jobs within the same framework. Data is available locally for repeated accesses to all users of the compute cluster regardless of the compute engine used. The lifecycle of the data on the compute nodes is hence disassociated with the job or framework which accesses it. With data sharing Alluxio ensures that no redundant copies of data are present in memory, driving down capacity requirements and thereby costs.
Applications leverage Alluxio’s simplicity and flexibility to continue accessing data as if they were running on remote object storage. Any results or transformations which need to be persisted can be done through Alluxio by configuring it to synchronously propagate changes to the underlying object storage system. This provides ease of management by ensuring that no data is lost. In addition, users have the option of storing temporary or intermediate data in Alluxio memory only, allowing for memory-speed writes.
Conclusion
The separation of compute resources from object storage makes for a cost-effective solution. By running Alluxio on nodes where the analysis occurs, key limitations of remote object storage are eliminated. Alluxio’s design makes it a key component of the data analytics stack required to exploit the performance potential of an architecture with disjoint compute and storage.
If you are interested in learning how to use Alluxio to derive timely insights from remote object storage, download our whitepaper which goes through setting up and using a computation cluster with Alluxio and Spark, along with a Ceph object storage cluster.