Alluxio Data Platform for AI and Analytics
Seamlessly access, manage, and run your data and AI workloads anywhere – on-prem, in the cloud, hybrid or multi-cloud.
How It Works
Uniquely positioned between compute and storage, Alluxio provides a single pane of glass for enterprises to manage data and AI workloads across diverse infrastructure environments with ease. By being close to storage, we have a universal view of the workloads on the data platform across stages of a data pipeline. This is the knowledge we tap into. Being close to compute is what makes the Alluxio Data Platform smart, by tapping into a view of what the applications on the compute engines are trying to achieve. Leveraging this unique position is what differentiates us from the myriad of offerings in the market.
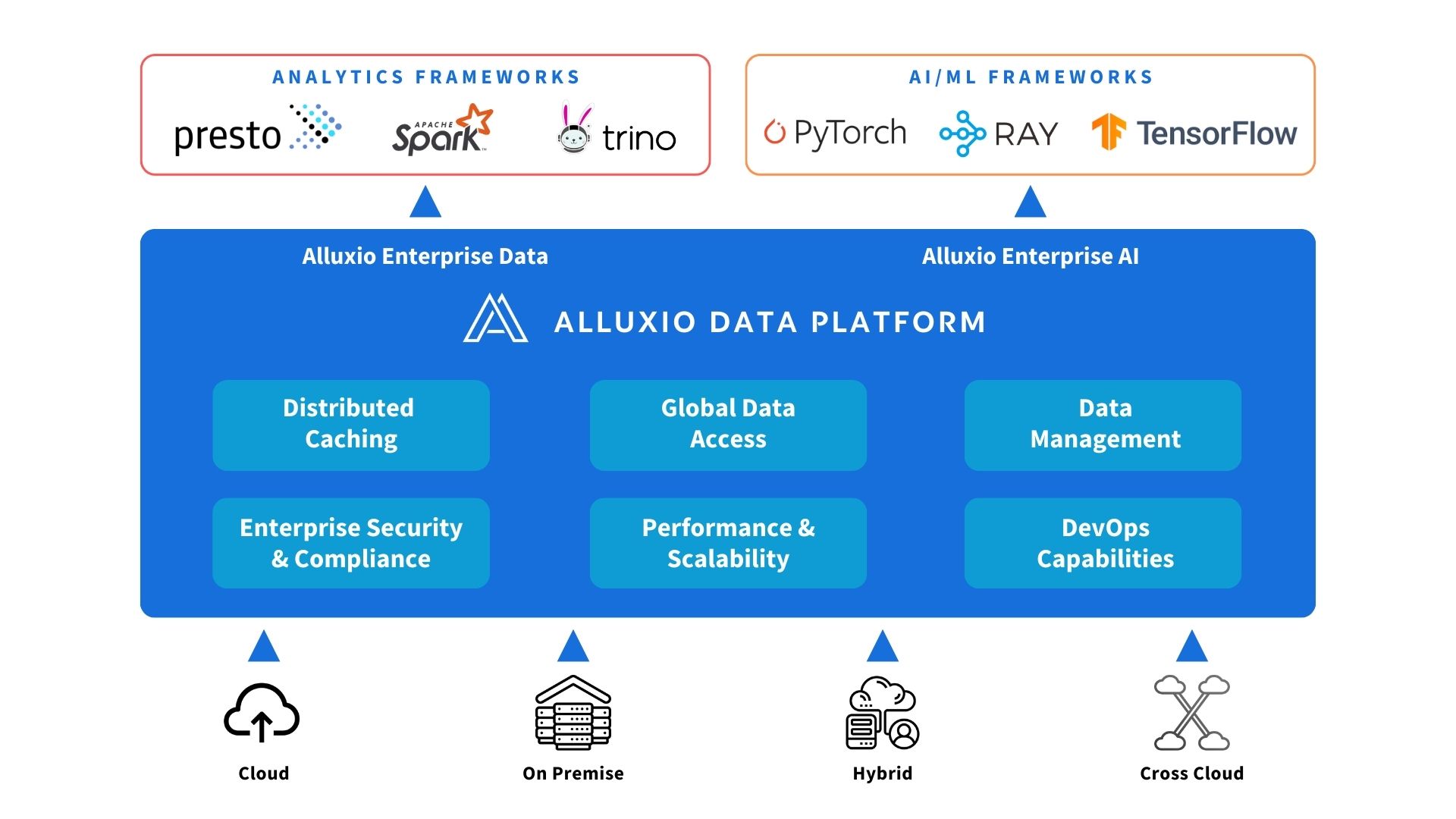
Alluxio Enterprise AI Benefits
Intelligent Caching Tailored to I/O Patterns of AI
Alluxio offers distributed caching so AI engines can read and write data through the high-performance Alluxio cache rather than slow data lake storage. Its intelligent caching strategies are tailored to the I/O patterns of AI workloads, providing high throughput and low latency across your AI pipeline.
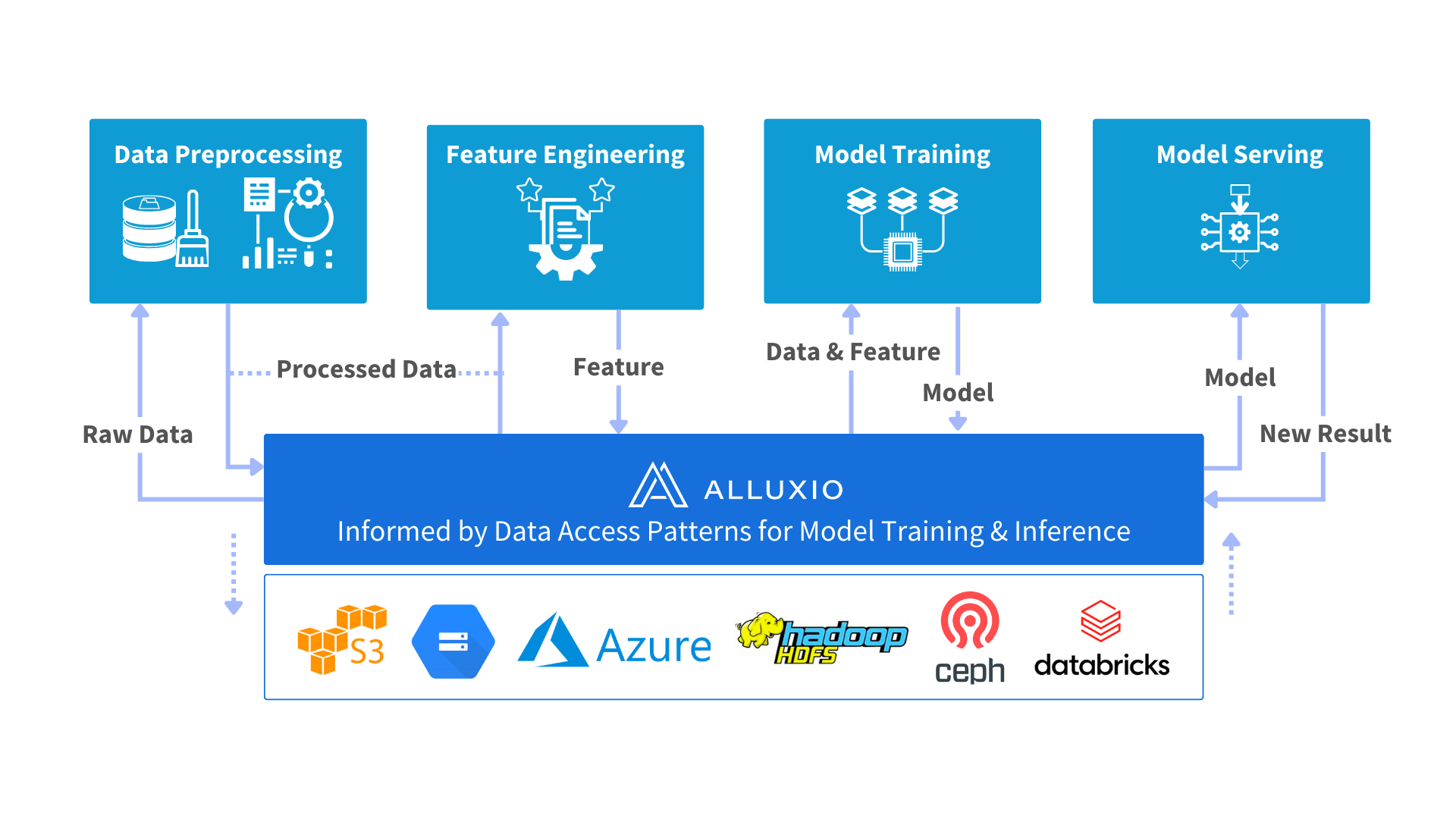
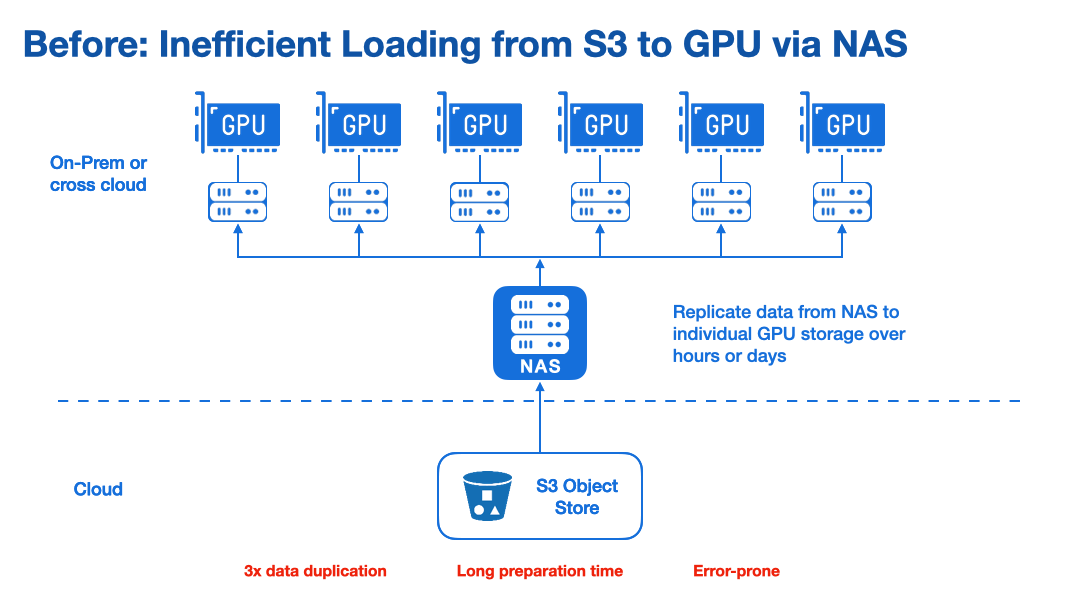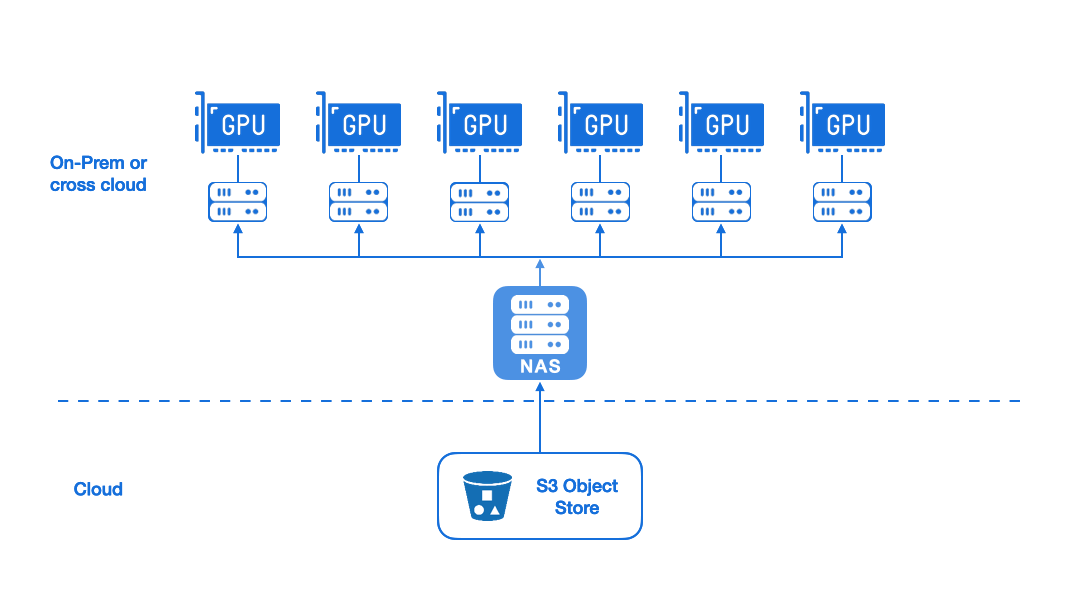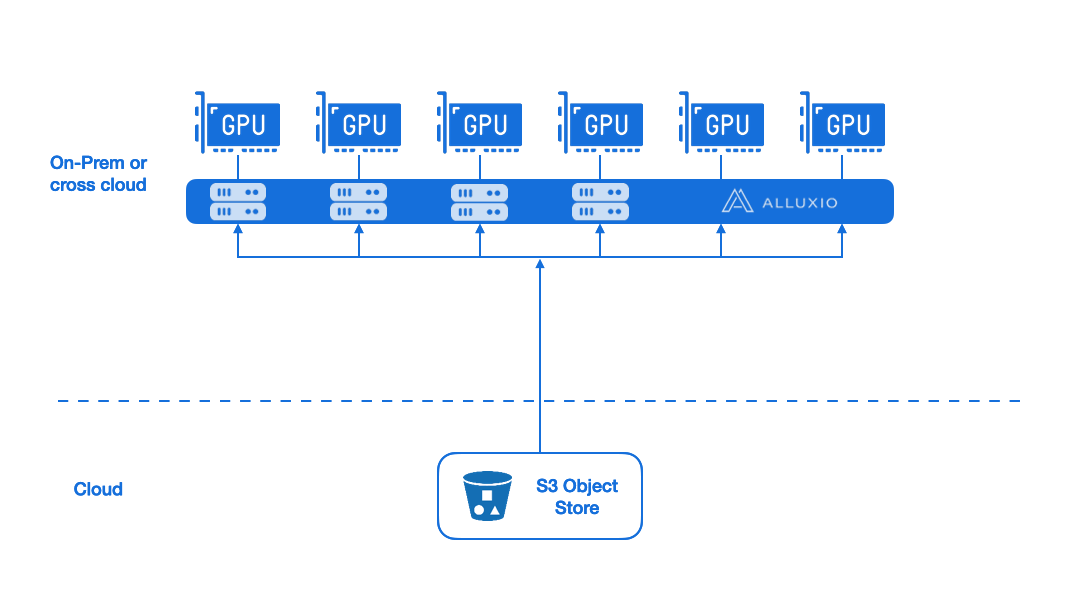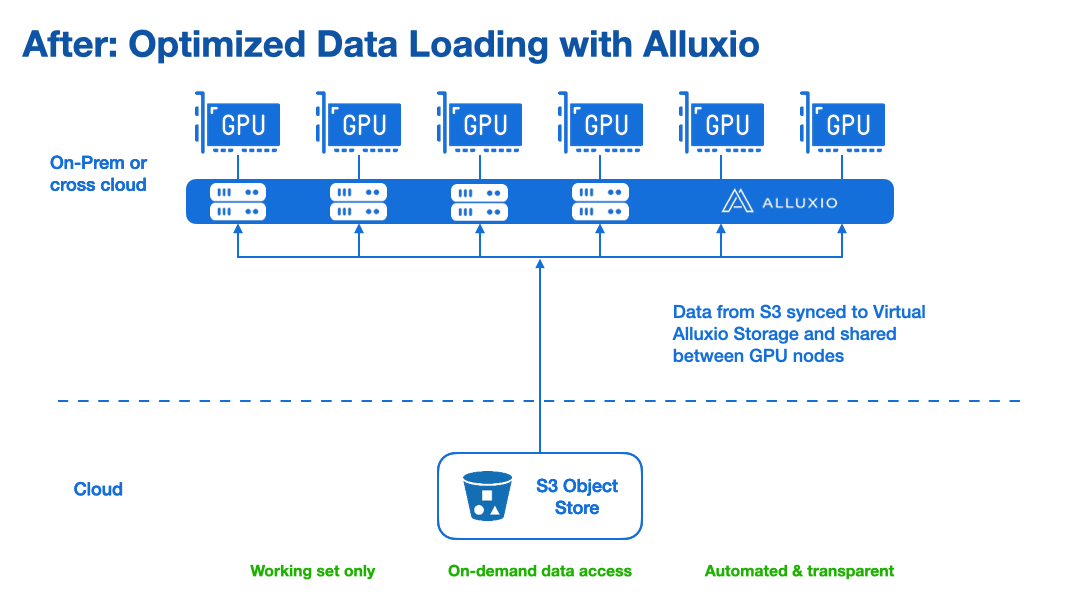
Efficient Data Loading Instead of Data Replication
Alluxio enables fast and on-demand data loading through instead of replicating training data to local storage. This removes data loading as the bottleneck for model training speed. With high-performance, on-demand data access, you can eliminate multiple data copies and improve performance.
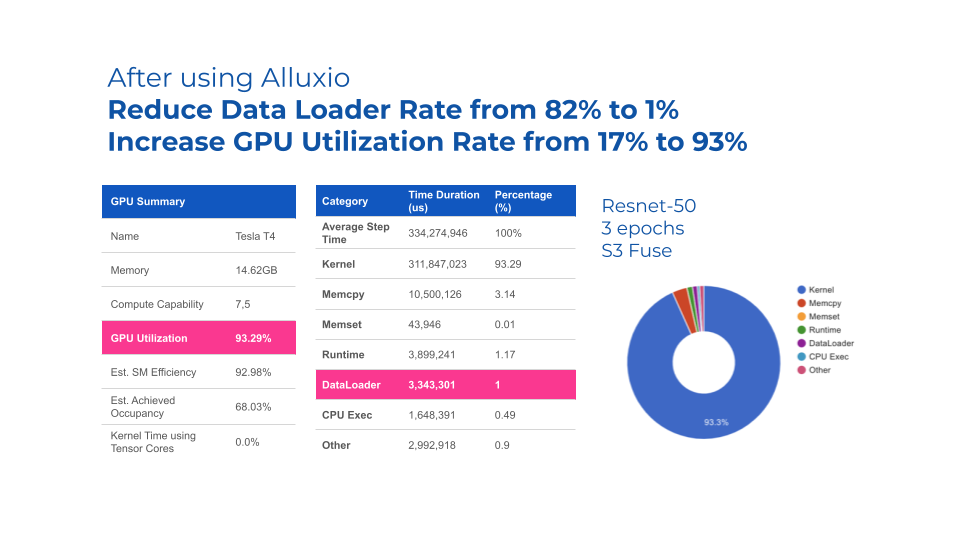
Maximize the ROI of Your AI Platform with up to 90% GPU Utilization
Alluxio increases your GPU utilization to up to 90%. It brings data up to speed with GPU cycles and accelerates model training and model serving. Alluxio also helps you turn commodity storage into as performant as specialized storage at a lower cost.
End-to-End Machine Learning Pipeline Demo
Alluxio’s Senior Solutions Engineer Tarik Bennett walks through a short end-to-end machine learning pipeline demo with Alluxio integrated. See how Alluxio can be provisioned or mounted as a local folder for the PyTorch dataloader, delivering 90%+ GPU utilization and dramatically accelerating data loading times.
1. Data Preparation
2. Setting up the Model
3. Setting up the PyTorch Profiler
4. Model Training
Alluxio Enterprise Data Benefits
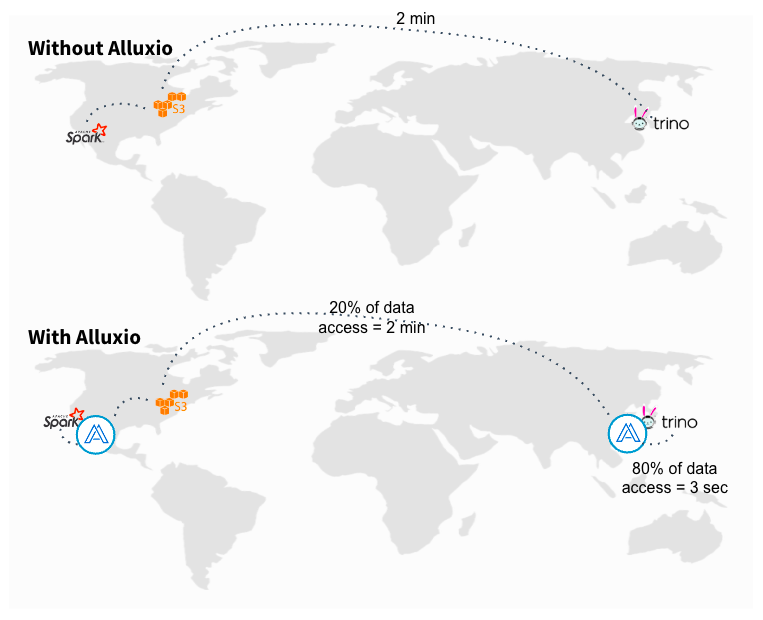
No More Copying Data
With Alluxio, you can connect any compute engine to any storage across any environment in any location.
Alluxio unifies data access no matter where your data resides, eliminating the need to move data to a single data lake or single cloud.
By bringing data closer to compute, Alluxio’s data caching capabilities speeds up large-scale analytics and AI workloads. And by eliminating copies and minimizing data movements, Alluxio reduces latency and saves bandwidth and egress costs.
No More Application Rewrites
With Alluxio, your data applications are easily portable across all environments.
Alluxio standardizes your data stack through a unified namespace, providing a single access model across all storage systems. Application developers no longer need to worry about where the data resides, and you can decouple compute and storage without worrying about application rewrites.
With Alluxio, spin up compute wherever it’s most cost effective, and your data platform gains true multi-cloud freedom.
Save on Data Infra Costs
Alluxio enables up to 70% in data infrastructure TCO savings, including reducing network egress costs and S3 API costs, enabling elastic compute, and saving platform operations costs.
By reducing the amount of data movement across the network, cloud egress costs are cut by half, and data infrastructure costs become more predictable. You not only understand where costs are allocated and but also have the levers to manage them.
As the only solution that provides a true separation between storage and compute, Alluxio future-proofs your data infrastructure, so you can easily adapt as your needs and tech stack evolve.
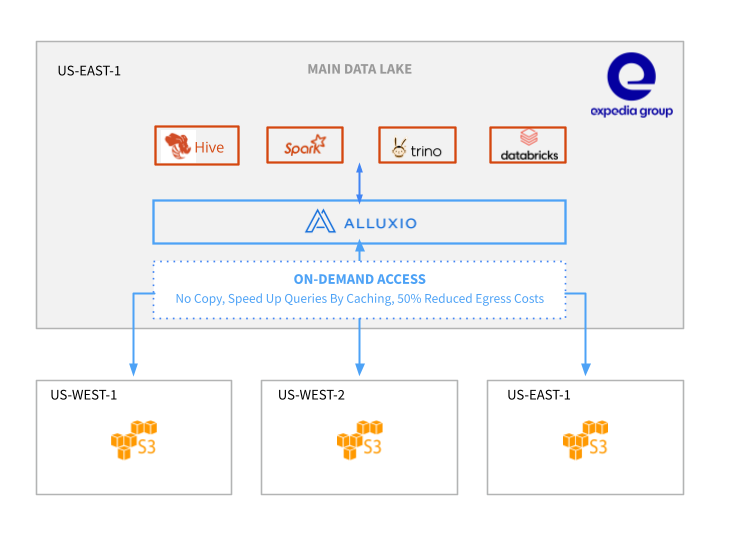
Expedia Case Study
“With the introduction of Alluxio, we are seeing better performance, increased manageability, and lowered costs. We plan to implement Alluxio as the default cross-region data access in all clusters in the main data lake.”
— Jian Li, Senior Software Engineer at Expedia

Ebook
PyTorch Model Training & Performance Tuning

PRODUCT DEMO
Solving the Data Loading Challenge for Machine Learning with Alluxio

WHITEPAPER
Efficient Data Access Strategies For Large-scale AI