Introduction
Many organizations deploy Alluxio together with Spark for performance gains and data manageability benefits. Qunar recently deployed Alluxio in production, and their Spark streaming jobs sped up by 15x on average and up to 300x during peak times. They noticed that some Spark jobs would slow down or would not finish, but with Alluxio, those jobs could finish quickly. In this blog post, we investigate how Alluxio helps Spark be more effective. Alluxio increases performance of Spark jobs, helps Spark jobs perform more predictably, and enables multiple Spark jobs to share the same data from memory. Previously, we investigated how Alluxio is used for Spark RDDs. In this article, we investigate how to effectively use Spark DataFrames with Alluxio.
Alluxio and Spark CachING
Storing Spark DataFrames in Alluxio memory is very simple, and only requires saving the DataFrame as a file to Alluxio. This is very simple with the Spark DataFrame write API. DataFrames are commonly written as parquet files, with df.write.parquet(). After the parquet is written to Alluxio, it can be read from memory by using sqlContext.read.parquet().
In order to understand how saving DataFrames to Alluxio compares with using Spark cache, we ran a few simple experiments. We used a single worker Amazon EC2 r3.2xlarge instance, with 61 GB of memory, and 8 cores. We used Spark 2.0.0 and Alluxio 1.2.0 with the default configurations. We ran both Spark and Alluxio in standalone mode on the node. For the experiment, we tried different ways of caching Spark DataFrames, and saving DataFrames in Alluxio, and measured how the various techniques affect performance. We also varied the size of the data to show how data size affects performance.
Saving DataFrames
Spark DataFrames can be “saved” or “cached” in Spark memory with the persist() API. The persist() API allows saving the DataFrame to different storage mediums. For the experiments, the following Spark storage levels are used:
MEMORY_ONLY: stores Java objects in the Spark JVM memoryMEMORY_ONLY_SER: stores serialized java objects in the Spark JVM memoryDISK_ONLY: stores the data on the local disk
Here is an example of how to cache a DataFrame with the persist() API:
df.persist(MEMORY_ONLY)
An alternative way to save DataFrames to memory is to write the DataFrame as files in Alluxio. Spark supports writing DataFrames to several different file formats, but for these experiments we write DataFrames as parquet files. Here is an example of how to write a DataFrame to Alluxio memory:
df.write.parquet(alluxioFile)
Querying “saved” DataFrames in Alluxio
After DataFrames are saved, either in Spark or Alluxio, applications can read them to computations. In our experiments, we created a sample DataFrame with 2 float columns, and the computation was a sum on both columns.
When the DataFrame is stored in Alluxio, to read the data in Spark is as simple as reading the file from Alluxio. Here is an example of reading our sample DataFrame in Alluxio.
df = sqlContext.read.parquet(alluxioFile)
df.agg(sum("s1"), sum("s2")).show()
We performed this aggregation on the DataFrame from Alluxio parquet files, and from various Spark persist storage levels, and we measured the time it took for the aggregation. The figure below shows the completion times for the aggregations.
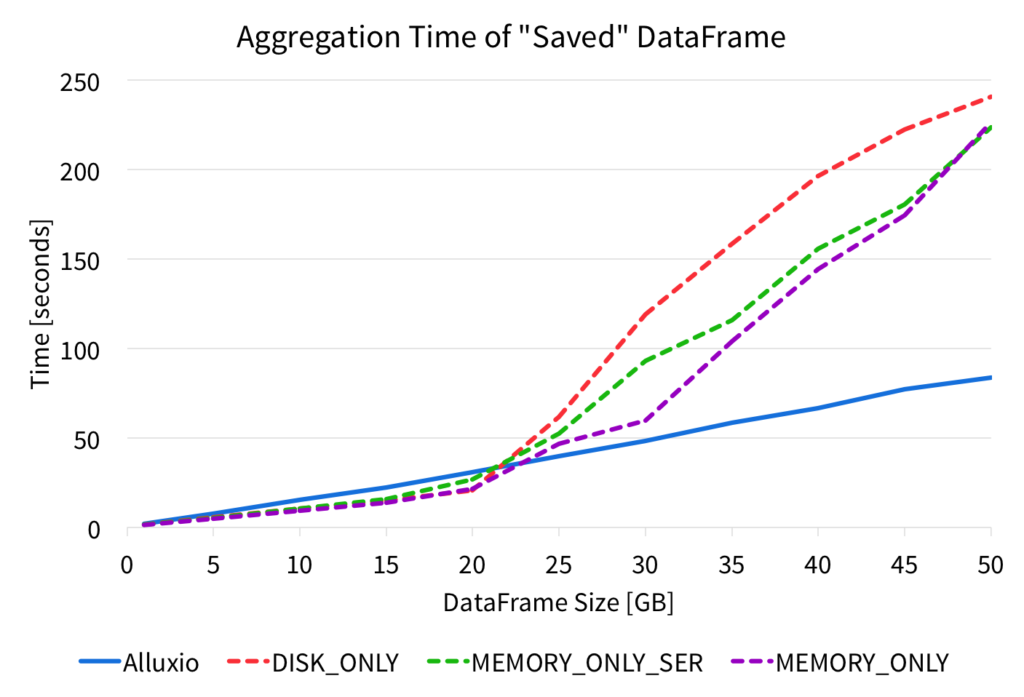
The figure shows that performing the aggregation on the DataFrame read from the Alluxio parquet file results in very predictable and stable performance. However, when reading DataFrames from the Spark cache, the performance is high for small data sizes, but larger data sizes significantly hurts the performance. For the various Spark storage levels, after about 20GB of input data, the aggregation slows down and increases significantly.
With Alluxio memory, the DataFrame aggregation performance is slightly slower than with Spark memory for smaller data sizes, but as the data size grows, reading from Alluxio performance significantly better as it scales linearly with the data size. Since the performance scales linearly, applications can process larger data sizes at memory speeds with Alluxio.
Sharing “saved” DataFrames with Alluxio
Alluxio also enables the ability to share data in-memory, even across different Spark jobs. After a file is written to Alluxio, that same file can be shared across different jobs, contexts, and even frameworks, via Alluxio’s memory. Therefore, if a DataFrame in Alluxio is frequently accessed by many applications, all the applications can read the data from the in-memory Alluxio file, and do not have to recompute it or fetch it from an external source.
To demonstrate the in-memory sharing benefits of Alluxio, we computed the same DataFrame aggregation in the same environment as described above. With the 50GB data size, we ran the aggregation in a separate Spark application, and measured the time it took to perform the computation. Without Alluxio, the Spark application must read the data from the source, which is the local SSD in this experiment. However, when using Spark with Alluxio, reading the data means reading it from Alluxio memory. Below are the results of the completion time for the aggregation.
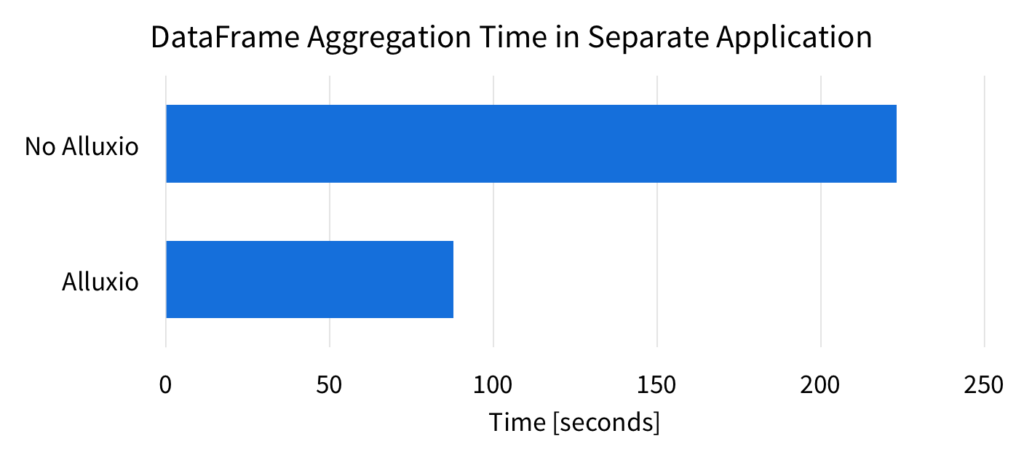
Without Alluxio, Spark has to read the data from the source again (local SSD). Reading from Alluxio is faster since the data is read from memory. With Alluxio, the aggregation is over 2.5x faster.
In the previous experiment, the source of the data was the local SSD. However, if the source of the DataFrame is slower or less predictable, the benefits of Alluxio is more significant. For example, Amazon S3 is a popular system for storing large amounts of data. Below are the results for when the source of the DataFrame is from Amazon S3.
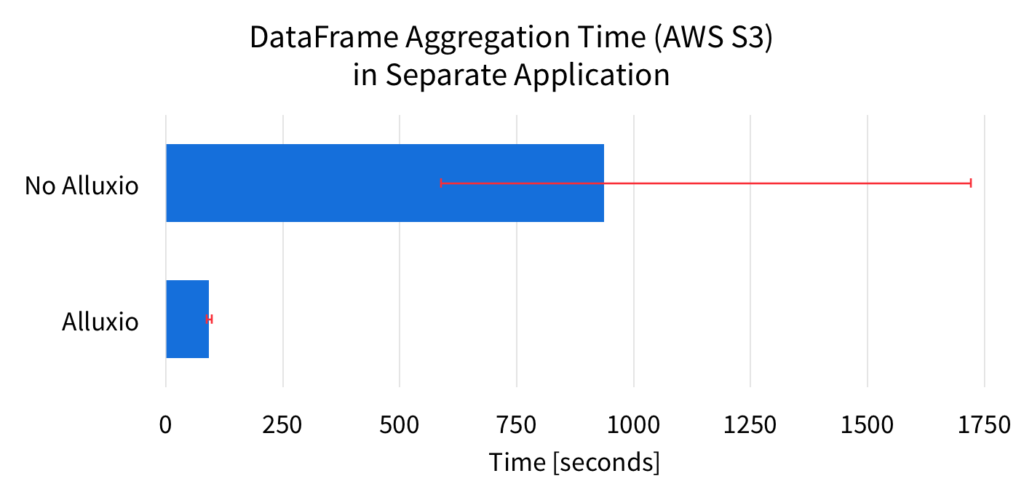
The figure shows the average aggregation completion time over 7 runs. The error bars in the figure represent the min and max range of the completion times. These results clearly show, that Alluxio significantly improves the average performance of the computation. This is because with Alluxio, Spark can read the DataFrame directly from Alluxio memory, instead of fetching the data from S3 again. On average, Alluxio speeds up the DataFrame computation over 10x.
Since the source of the data is Amazon S3, Spark without Alluxio has to fetch the data over the network, and this can result in unpredictable performance. This unstable performance is evident from the error bars of the figure. Without Alluxio, the Spark job completion times widely vary, by over 1100 seconds. With Alluxio, the completion times only vary by 10 seconds. Alluxio reduces the unpredictability by over 100x!
Because of the S3 network unpredictability, the slowest Spark run without Alluxio can take as long as over 1700 seconds, almost twice as slow as the average. On the other hand, the slowest Spark run with Alluxio is around 6 second slower than the average time. By considering the slowest runs, Alluxio speeds up the DataFrame aggregation by over 17x.
Conclusion
Alluxio helps Spark be more effective by enabling several benefits. This blog demonstrates how to use Alluxio with Spark DataFrames, and presents performance evaluations of the benefits.
- Alluxio can keep larger data sizes in memory to speed up Spark applications
- Alluxio enable sharing of data in-memory
- Alluxio provides stable and predictable performance