The Alluxio sandbox is the easiest way to test drive the popular data analytics stack of Spark, Alluxio, and S3 deployed in a multi-node cluster in a public cloud environment. The sandbox cluster is fully configured and ready for users to run applications ranging from the hello-world example to the TPC-DS benchmark suite. Don’t take our word for it; kick off the benchmark yourself to see the performance benefits of running Spark jobs that interface through Alluxio on S3 compared to running Spark jobs directly on S3. It is extremely easy to request and launch a sandbox cluster as a playground for 24 hours at no cost to you.
Cluster details
The sandbox cluster consists of 2 master nodes and 4 workers nodes using r4.2xlarge EC2 instances. Alluxio, currently at version 1.8.1, is configured to use a S3 bucket as its root under file storage. It is deployed in high availability mode with leading and backup master nodes. To run TPC-DS, Apache Spark is deployed with its master on the first master node and a worker on each of the worker nodes. Note that the Spark workers are co-located with the Alluxio workers to possibly leverage data locality provided by Alluxio local file system in memory.

Performance benchmarking
TPC-DS is an industry standard benchmark suite, measuring performance on workloads that derived from real-world scenarios. We follow the experiment conducted by Databricks in this blog post and run 3 groups of queries: interactive, reporting and deep analytics; reporting the cumulative runtime as a result. The 26GB dataset is pre-generated and copied to a new S3 bucket as part of creating the sandbox cluster.
To generate the baseline – the control run is executed. We run the benchmark with a S3 bucket as the input and for the output directories.
For the run with Alluxio, we preload the dataset into Alluxio, distributing a copy of the dataset amongst its workers. This simulates the scenario where the storage local to the compute provided by Alluxio is hydrated and data is warmed up. This approach is typical for Alluxio deployments.
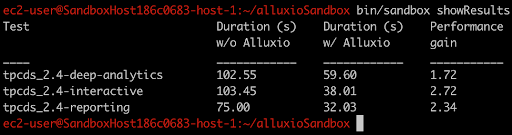
The benchmark is run with an Alluxio URI as the input and output directories. Below is a sample output of the two iterations:
The results
We have seen that the run with Alluxio providing data locality to compute nodes typically shows a performance improvement ranging from from 45% to 300% depending on the time of day. This is with a stack running solely on AWS; for hybrid cloud scenarios, such as Spark and Alluxio in AWS using data from an on premise HDFS cluster, the performance improvement can be greater, depending on the network speed between the on premise storage cluster and the public cloud. We have seen a range of numbers from our open source community users, up to 10x improvement.
Improving analytic and machine learning workloads even by 50% can have a huge impact; both decreasing the cost of computing resources and increasing the efficiency of data analysts, enabling them to run more reports or develop more models. As an example, in this run we see that the total time of the 3 runs without Alluxio was 281 seconds and with Alluxio was 129.64 seconds; equating to a total performance gain of x2.17. This reduction in time means that computing resources can be taken down faster to reduce costs.
Come get your sandbox!
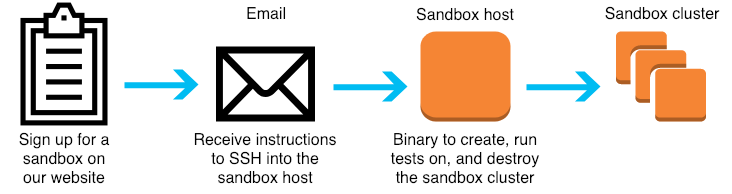
After signing up on our website, you will receive an email with instructions to SSH into an EC2 instance. From this instance, you can freely manipulate the sandbox cluster via a binary that issues the commands to create, run tests on, and destroy the cluster. Feel free to SSH into the cluster and edit configurations or restart processes; you can always destroy and recreate the cluster to restore its initial state. Note the upkeep costs for the EC2 instances are covered by Alluxio and so the sandbox cluster will only be available for 24 hours.
Your Feedback
We hope that the sandbox stack of Spark and S3 is familiar to many of our users, but this is only one of many combinations that can work with Alluxio. If you would like to see a different sandbox stack using other compute frameworks and/or storage systems, we’d love to hear from you. Reach out to us at info@alluxio.com; any feedback about the sandbox is always appreciated.