Overview
An Alluxio cluster caches data from connected storage systems in memory to create a data layer that can be accessed concurrently by multiple application frameworks. This greatly improves performance for many analytics workloads. On-demand caching occurs when clients read blocks of data using a ‘CACHE’ read type from persistent storage systems connected to the Alluxio cluster.
Prior to Alluxio v1.7, on-demand caching was on the critical path of read operations, requiring a full block to be read before the data was available for the application. Workloads which read partial blocks, for example SQL workloads, would be adversely affected on initial reads from connected storage. For example, when reading the footer of a parquet file, the client only requests a small amount of data, but the client reads the entire data block in order to cache it.
Beginning with Alluxio v1.7 on-demand data caching is improved by removing it from the critical path of reading data and making it an asynchronous operation on the worker. Asynchronous caching simplifies the role of the application client in data caching and can significantly improve the performance of certain workloads. This post explains data caching behavior in Alluxio v1.7 and later versions, and provides tips on how to best utilize the feature. The topics covered include:
- Asynchronous caching strategy
- Tuning and configurations for asynchronous caching
- Advantages of asynchronous caching
Asynchronous Caching Strategy
Asynchronous caching pushes all caching responsibilities to the worker and partially read blocks are always scheduled to be cached in the background (unless the user specifies a NO_CACHE read type). Additionally , the partial caching parameter alluxio.user.file.cache.partially.read.block, is no longer required since there is no performance impact on the client when reading either a full or partial block.
When reading from a connected storage system with a CACHE read type, data will be synchronously cached if a block is read sequentially from beginning to end. This is an optimization that takes advantage of the fact that the worker will already have fetched the full data block. In the case where the block is not fully read, the client will send an async cache command to the worker and continue processing. At some later time, the worker will fetch the complete block from the under store. The following figure shows the synchronous portion of a partial block read.
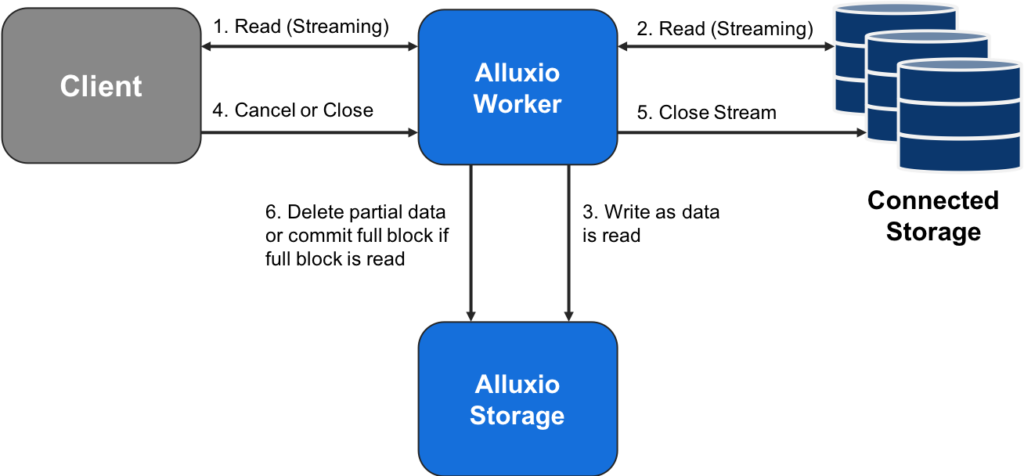
In Figure 1, the client only reads as much data as required. If a full block is read the data will be cached, otherwise the worker will cache the remainder of the block asynchronously as follows in Figure 2.
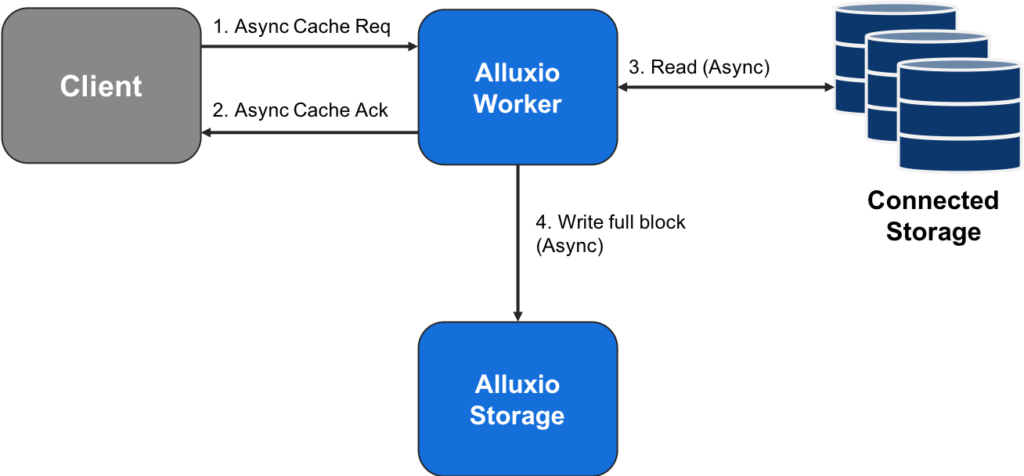
The async cache request is a lightweight RPC between client and worker. The client is free to move on with processing immediately after the worker acknowledges the request, and steps 3 and 4 can occur asynchronously in the background.
Tuning and Configurations for Async Caching
Alluxio workers perform asynchronous caching in the background in parallel with serving synchronous read requests from the client. Each worker has a thread pool, whose size is specified by the parameter “alluxio.worker.network.netty.async.cache.manager.threads.max”. The default value is 8, meaning a worker may use up to 8 cores to download blocks from other workers or the UFS and cache them locally for future service. One can tune this value higher to speed up the background async cache traffic at the cost of increased CPU usage. Lowering the value will have the opposite effect, slowing down the async cache traffic while freeing up CPU resources.
Advantages of Async Caching
A simple example which showcases the advantage of async caching is reading a small portion of a file from the connected storage system, but with the intent of caching it because future small reads are expected. With async caching, reading the first 5KB of a file with 512MB blocks from S3 takes on the order of seconds and the client is free to move on with processing. With partial caching in earlier releases, this initial read would take on the order of minutes in order to cache the full block (the speeds will depend on the network connection).
In both cases, the data block is fully cached in Alluxio minutes after the initial request, but now with async caching, the initial reader is free to continue execution after reading the data it required while the full block is cached in the background.
Async caching greatly improves the cold read performance of workloads which do not necessarily have full sequential read patterns, for example when running SQL workloads on compute frameworks like Presto or SparkSQL. With async caching, the first query will take a similar amount of time as reading directly from connected storage, and the overall performance of the cluster will gradually improve as data is asynchronously fetched into Alluxio.
Future Work
Managing Alluxio storage is a critical aspect of the Alluxio system. The async caching mechanism will be further improved on in future releases. Some of the improvements on this feature include
- Remove the concept of passive caching (ALLUXIO-3136)
- Finer grained control on the resource usage, ie. network bandwidth, of async caching (ALLUXIO-3137)
- Improved worker to worker data transfer mechanism (ALLUXIO-3138)
- Optimize async caching data reads (ALLUXIO-3141)