In this blog, I’ll explore the challenges our customers are facing with storing data long term in Hadoop, and discuss what the Hitachi Content Platform team is doing to help our customers solve these challenges with the help of Alluxio.
The Big Data Problem with Hadoop
Data is at the center of our digital world and for years Hadoop has been the go-to data processing platform because it is fast and scalable. While Hadoop has solved the data storage and processing problem for the last ~10 years, it achieves this by scaling storage and compute capacity in parallel. As a result, Hadoop environments have continued to expand compute capacity well beyond their needs as more and more of the storage is consumed by older, inactive data.
Although HDFS is effective at storing small-to-mid size repositories of data, HDFS becomes vastly more costly and inefficient as storage needs expand, since this requires increasing both storage and compute. HDFS also relies on data replication (storing multiple copies of each object) for protection. As these data sets grow into the petabytes the growing cost of old data and idle compute in your Hadoop ecosystem will become unsustainable.
Offloading Solution
Every storage administrator is thinking about how they can reduce the cost of data storage while still getting the best performance out of their hardware. With this in mind, Apache Hadoop has been continually improving the concept of tiered storage, and in Hadoop 2.6 many improvements to the tiered storage concept have been added. These features allow you to attach a storage policy to a directory, categorize it as Hot, Warm, Cold, or Frozen, and define how many block replicas of the data to keep for that policy. Although storage administrators can reduce the number of copies of data they have to store, they still have the challenge of compute sitting idle. This is where offloading data outside of HDFS can offer huge benefits.
How Can Object Storage Help Reduce My HDFS Footprint?
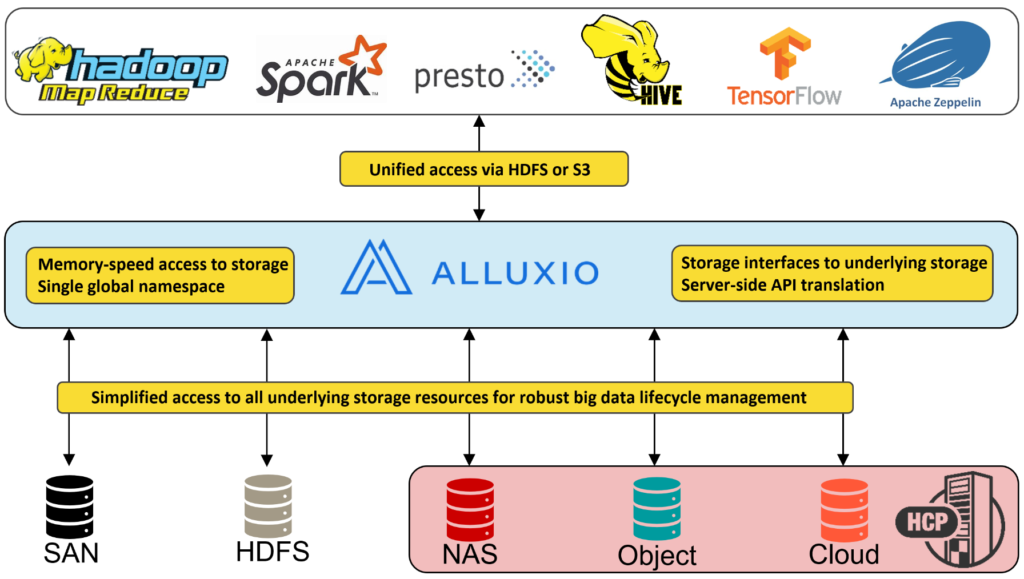
Object storage offers significant cost savings to customers by increasing density and providing greater control over data. Offloading data from Hadoop to an object store like Hitachi Content platform (HCP) enables customers to unlock a new, cheaper storage tier. The Hitachi Content Solutions engineering team is working with Alluxio to bring in memory caching and object store efficiencies to existing big data challenges.
Alluxio is a memory-speed, virtually-distributed storage layer that enables any application to interact with any data from any storage at memory speed. With Alluxio and HCP, HDFS applications can virtualize object storage and move data from HDFS to object storage through a single protocol and interface.
Why Hitachi Content Platform and Alluxio?
When configuring Hitachi Content Platform as a understore or a mounted directory in the Alluxio filesystem, applications can simplify and expand their data ecosystem. In this environment, Hadoop applications can read and write data to and from the HCP and Hadoop filesystems. Applications can move data from HDFS to Object storage as simply as moving data from one directory to another.
With Alluxio caching, data can be recalled from HCP to the Alluxio in-memory file system on the Hadoop node, enabling memory speed analytics with object store savings. With HCP and Alluxio, applications can unify data access protocols and offload cold data to cost effective storage.
Looking Ahead
In Part 2, I’ll discuss how the new functionality in Hadoop 3.1 brings object storage closer to the Hadoop ecosystem and how future functionality will continue to simplify big data management. Read the next Blog Post.
Check out our Demo Videos and download Alluxio to get started.